2020 AI College (AI 양재 허브) 실무 과정 - 퀴즈 목록
'2020 AI College (AI 양재 허브) 실무 과정'에서 배운 내용 복습 겸 가볍게 푼 퀴즈들입니다. 쭉 읽어보면서 개념을 다시 되살려볼 수 있고, 나아가 면접에도 대비할 수 있을 것입니다.
<회귀>
# 회귀 분석 (Regression)
Q. 아래 그래프는 회귀 분석에 대한 예시입니다. 아래 그래프와 회귀 분석에 대해 '틀린' 설명을 고르세요.

-Y = beta_0 + beta_1 * X의 식을 통해 선형 회귀 분석을 하고 있다.
-회귀 분석이란, 입력 데이터가 어떤 클래스에 속하는지 예측하기 위한 알고리즘이다. *
-Loss Function 을 통해 데이터에 가장 잘 맞는 회귀 선을 찾는다.
-Gradient Descent은 거꾸로 된 산을 내려오는 것처럼 설명될 수 있다.
# K-Fold Cross Validation
Q. K-Fold에서 K가 10인 경우, 데이터의 구성과 학습 과정에 대해 옳은 설명을 고르시오
-학습 데이터와 검증 데이터를 같은 비율로 나누고 10번 학습시킨다.
-데이터를 10등분을 하여 9개는 학습 데이터로 1개는 검증 데이터로 사용하되 반복하면서 검증 데이터를 변경한다. *
-전체 데이터를 10번 학습하고 그중 10%를 뽑아 검증 데이터로 사용한다.
-데이터 세트를 10등분을 하여 9개는 학습 데이터로 1개는 검증 데이터로 고정하여 사용한다.
# 회귀분석이란
Q. 땅 면적에 따른 땅 가격을 회귀 분석을 통하여 분석하고자 합니다. 이에 대한 설명으로 옳지 않은 것을 고르세요.
-feature 데이터는 땅 면적에 대한 데이터를 의미합니다.
-label 데이터는 땅 가격에 대한 데이터를 의미합니다.
-회귀 분석은 feature 데이터와 label 데이터 간의 관계를 근사선을 사용하여 근사하고 예측합니다.
-회귀 분석 모델을 사용하면 땅 가격에 대한 예측된 면적을 구할 수 있습니다. *
# 회귀 분석 모델
Q.회귀 분석 모델에 관한 설명으로 옳지 않은 것을 고르세요
-회귀 분석 모델은 feature 데이터를 입력을 받아 label 데이터를 출력합니다. *
-회귀 분석 모델은 벡터를 사용한 수식으로 표현 가능합니다.
-데이터 간의 상관 관계를 잘 이해하고 있다면, 데이터를 보다 잘 근사하는 회귀 분석 모델을 선택할 수 있습니다.
-회귀 분석 모델의 하이퍼 파라미터를 튜닝하는 것으로 모델을 데이터에 보다 잘 근사하게 만들 수 있습니다.
# Loss 함수 정의 및 계산
Q. Loss 함수에 대한 설명을 옳지 않은 것을 고르세요.
-Loss 함수는 MSE로만 정의합니다. *
-성능이 떨어지는 모델은 loss 값이 높게 나옵니다.
-MSE는 오차의 제곱의 평균입니다.
-MSE 값이 작게 나왔다면 예측을 잘했다고 생각할 수 있습니다.
# least square 최적화
Q. least square 최적화에 대한 설명으로 옳지 않은 것을 고르세요.
-선형 회귀 모델의 loss 함수는 선형 파라미터의 2차 함수로 표현됩니다.
-선형 회귀 모델의 loss 함수는 항상 최소값이 존재합니다.
-least square 방식은 단순 선형 회귀 모델에서 최적의 선형 파라미터를 구할 수 있게 합니다.
-least square solution 값을 구하기 위해서는 feature 데이터 외의 값은 필요하지 않습니다. *
# 단순 선형 회귀 평가
Q.선형 회귀 평가 기법에 대한 설명으로 옳지 않은 것을 고르세요.
-RMSE는 MSE의 양의 제곱근이다.
-RMAE는 RMSE와 마찬가지로 0에 가까워질수록 예측을 잘 한 모델이라 할 수 있다.
-R2는 모델이 label 값과 비슷할 수록 1에 가까운 값을 갖습니다.
-Adjusted R2는 샘플의 개수 대비 feature column의 개수가 많은 경우 값이 증가한다. *
(해설) 샘플의 개수 대비 feature column의 개수가 많은 경우, 모델의 복잡성이 증가합니다. Adjusted R2는 R2에서 이러한 모델 복잡성 문제를 추가한 모델로 기존 R2 값에 비해서 샘플의 개수 대비 feature column의 개수가 많으면 값이 줄어들게 됩니다.
# 최적화 기법과 Greedy 알고리즘
Q. Greedy 알고리즘에 대한 설명으로 옳은 것을 고르세요.
-greedy 알고리즘의 탐색 범위가 넓을수록 더 정확한 최소값 또는 최대값을 찾을 확률이 높아진다. *
-greedy 알고리즘을 수행하면 단순 선형 회귀 모델 loss 함수의 최대값을 찾을 수 있다.
-greedy 알고리즘은 무한 범위에서 탐색이 가능하다.
-단순 선형 회귀에서는 greedy 알고리즘으로 loss 값을 최소로 만드는 파라미터를 구할 수 없다.
# 경사 하강하기
Q. loss 함수의 최소값을 찾는 경사 하강 방법을 나타낸 아래 그림에 대한 설명으로 옳지 않은 것을 고르세요.
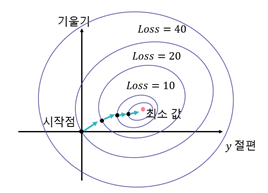
-loss 함수를 y절편 값을 x축, 기울기 값을 y축으로 설정한 그림이다.
-같은 원 위의 loss 값들은 모두 같다.
-최소 값 지점의 위치 좌표가 최적의 선형 파라미터 값이다.
-시작점에서 처음 움직이는 방향은 최소값 위치를 향한 방향이다. *
(해설) 시작점에서 움직이는 방향은 그 위치에서 가장 가파른 경사 방향입니다.
# Gradient descent 알고리즘
Q. Gradient descent 기법에 대한 설명으로 옳은 것을 고르세요.
-loss 함수는 항상 최소 값을 갖는다. *
-특정 선형 파라미터 포인트(w0, w1 등등)에서의 gradient는 최소의 loss 값의 위치를 향하는 방향이다.
-gradient descent 방식으로 선형 파라미터를 업데이트 할 때마다 loss 값은 작아진다.
-learning rate가 너무 작으면 최소 loss 값을 찾을 수 없다.
# Gradient descent 보완
Q. Gradient descent 방식의 단점에 대한 설명으로 옳지 않은 것을 고르세요.
-단순 선형 회귀 모델에서의 loss 함수는 유일한 최소값을 갖기에 local minima 문제가 생기지 않습니다.
-learning rate가 너무 큰 경우 loss 값이 증가할 수 있습니다.
-learning rate를 조정하기 위해서 iteration이 증가함에 따라 크게 하는 방법이 있습니다. *
-초기값이 최소값 위치에 가깝다면 보다 빠르게 최소값에 도달할 수 있습니다.
# Gradient descent를 사용한 단순 선형 회귀
Q. Gradient descent 방식을 사용한 단순 선형 회귀 방식에 대한 설명으로 옳지 않은 것을 고르세요.
-gradient 방식의 local minima 문제를 해결하기 위하여 loss 함수를 MSE로 정의한다.
-learning rate의 크기에 따라 최소 loss 값에 도달하는 횟수를 조절할 수 있다.
-파라미터의 초기값 정보를 얻기 위해서 데이터의 분포를 살펴보는 것은 도움이 된다.
-gradient descent를 사용한 단순 선형 회귀는 least square solution 보다 정확하다. *
(해설) gradient descent로 찾은 위치는 최소값 위치를 근사한 값입니다. 따라서 정확히 그 위치를 구한 least square solution이 보다 정확한 solution이라 할 수 있습니다.
첫 번째 보기: local minima 문제는 함수가 non-convex할 때 생기는데 (convex: 이차함수처럼 둥근 꼭지점이 하나만 있을 때), MSE는 이차함수 꼴이라서 local minima 문제가 안 생긴다.
# 다중 선형 회귀
Q. 다중 선형 회귀 모델에 대한 설명으로 옳지 않은 것을 고르세요.
-예측값을 구하기 위해선 p개의 변수 데이터가 필요합니다.
-학습 후, p+1개 최적의 선형 파라미터를 구할 수 있습니다.
-least square solution을 사용하여 학습을 수행할 수 있습니다.
-gradient descent를 사용하여 학습할 수 없다. *
# 다항 선형 회귀
Q. 다항 선형 회귀에 대한 설명으로 옳은 것을 고르세요.
-이차항 선형 회귀 모델은 least square solution을 사용할 수 없다.
-2개 이상의 feature column이 존재 하는 학습 데이터는 고차항 선형 회귀를 사용할 수 없다.
-고차항 모델의 차수가 높을수록 성능이 올라간다.
-scikit-learn에서는 고차항 선형 회귀를 수행하기 위해서 `PolynomialFeatures`를 활용한다.
# 다항 선형 회귀와 정규화 기법
Q. 다항 선형 회귀의 정규화 기법에 대한 설명으로 옳지 않은 것을 고르세요.
-다항 선형 회귀 모델의 고차항의 차수가 높을수록 과적합이 일어나기 쉽다.
-릿지 정규화 방식은 MSE에 규제항을 더하여 loss 함수를 정의한다.
-규제항의 하이퍼 파라미터는 least square로 조절할 수 있다. *
-엘라스틱 넷 정규화는 릿지와 라쏘 정규화 기법을 일정 비율로 합하여 정의합니다.
<분류>
# Average Precision
Q. 다음과 같은 순서로 문서가 예측되었을 때의, Average Precision을 계산해보세요.
XOXXOOOXOO (O가 예측 성공)
(해설) (0.50+0.40+0.50+0.57+0.56+0.60) / 6 = 0.52
# Classification VS Regression
Q. Classification과 Regression에 대한 설명으로 옳지 않은 것은?
-Classification은 discrete value을 예측하는 모델이다.
-Regression은 continuous value를 예측하는 모델이다.
-Linear Regression은 Classification으로 확장 및 적용 가능하다. *
-Classification은 Cost Function으로 MSE를 사용하지 않는다.
# 회귀와 분류의 차이점
Q. 회귀(Regression)과 분류(Classification)에 대한 설명으로 옳지 않은 것은?
-회귀는 회귀 식을 통해 주어진 데이터에 대한 결과 값을 예측한다.
-분류는 주어진 입력이 어느 클래스에 속하는지 판별하는 것이다.
-선형 회귀의 식은 별다른 변형 없이 분류에 바로 적용가능하다. *
-로지스틱 회귀에서 0 또는 1 사이의 값을 내보내는 Logistic function(Sigmoid)이 사용된다.
# Confusion Matrix
Q. Confusion Matrix에 대한 설명으로 옳지 않은 것은?
-Accuracy은 (TP+TN) / (TP+TN+FP+FN) 로 나타날 수 있다.
-Precision은 TP / (TP +FP) 로 나타날 수 있다.
-Recall은 TP / (TP + FN) 로 나타날 수 있다.
-Confusion matrix는 binary classification에서만 사용 가능한 행렬이다. *
# PR-curve
Q. PR-curve에 대한 설명으로 옳지 않은 것은?
-x축이 Recall, y축이 Precision인 그래프이다.
-이상적(예측이 항상 정답)일 경우, Recall이 변함에 따라 Precision이 항상 1이다.
-다음으로 예측한 값이 정답에 속할 때, Precision과 Recall은 모두 증가한다.
-다음으로 예측한 값이 오답에 속할 때, Precision과 Recall은 모두 감소한다. *
# Classification의 종류
Q.Classification의 종류에 속하지 않은 것은?
-Softmax Regression
-Naïve Bayes Classifier
-Linear Regression *
-Support Vector Machine
# Binary Classifier
Q. Binary Classifier로 작동할 수 있는 것을 모두 고르시오.
-K-Nearest Neighbor *
-Support Vector Machines *
-Decision Tree *
-Neural Networks *
# 이진 분류에서의 TP, FP, FN, TN
Q. 암을 양성과 음성으로 구분하는 이진 분류 문제에 대한 4개의 개념 중 옳은 설명을 고르세요.
-True Positive : 음성인데, 양성으로 잘못 검출된 것
-False Positive : 양성인데, 양성으로 제대로 검출된 것
-True Negative : 양성인데 ,음성으로 잘못 검출된 것
-False Negative : 양성인데, 음성으로 잘못 검출된 것 *
# 분류 지표(metric) 공식
Q. 다음 중 분류 지표(metric) 공식 표기가 다른 것은?
-Accuracy = ( TP + TN ) / ( P + N )
-Precision = ( FP ) / ( TP + FP ) *
-Recall = ( TP ) / ( TP + FN )
-FPR = ( FP ) / ( FP+TN )
# SVM의 kernel trick
Q. SVM에서 사용되는 kernel trick의 주된 목적은?
-Binary classification 하기 위함이다.
-Multi-class classification 하기 위함이다.
-Linear classification 하기 위함이다.
-현재 input을 high-dimensional feature space로 mapping 하기 위함이다. *
# SVM
Q. SVM에 대한 설명으로 옳은 것을 모두 고르시오.
-SVM은 linear classification으로 사용할 수 있다. *
-SVM은 kernel trick을 활용하여 non-linear classification 문제를 푼다. *
-SVM은 Lagrangian 개념을 도입하여 최적화 문제를 푼다. *
-SVM은 multi-class classifier로 사용될 수 없다.
# 서포트 벡터 머신
Q. 서포트 벡터 머신(SVM)에 대한 설명으로 옳지 않은 것은?
-결정 경계의 마진(margin)을 가장 크게 하면서 모델을 학습한다.
-서포트 벡터(support vector)는 결정 경계에 가장 가까운 데이터이다.
-Soft 마진을 활용할 때는 한 개의 데이터라도 오차를 허용하지 않는다. *
-고차원 데이터의 분류가 가능하다.
# Validation problem
Q. Training dataset에서의 정확도가 100%이고, Validation dataset에서의 정확도가 70%일 때 다음 중 어떤 것을 살펴보아야 할까?
-Underfitting
-Nothing. Model is perfect
-Overfitting *
# Naïve Bayes Classifier & kNN
Q. Naïve Bayes Classifier와 kNN에 대한 설명으로 옳지 않은 것은?
-Naïve Bayes Classifier는 조건부 독립을 가정한다.
-1-NN은 overfitting 될 확률이 높다.
-kNN은 학습을 통해 classifier를 찾는다. *
-K=N이면 (K가 데이터 크기라면) 클래스 중 단순히 가장 많은 것의 개수로 분류한다.
<의사결정트리 & 앙상블>
# 의사결정트리 구조
Q. 의사결정트리의 구성 요소가 아닌 것은 무엇인가요?
-뿌리 노드 (Root Node)
-내부 노드 (Internal Node)
-외부 노드 (External Node) *
-리프 노드 (leaf Node)
# 의사결정트리의 특성
Q. 의사결정트리의 특성이 아닌 것을 모두 고르세요.
-분류 결과가 해석가능하다.
-의사결정트리의 학습은 일반적으로 탐욕적(Greedy)으로 진행된다
-손실 데이터(missing data) 처리가 쉽다.
-분류를 위한 알고리즘이기 때문에 회귀에는 사용할 수 없다. *
-학습 전 데이터의 전처리 과정이 반드시 필요하다. *
# 앙상블 학습 투표 방식
Q. 앙상블 학습의 투표 방법 중 잘못된 것을 고르세요.
-앙상블 학습을 통한 분류에는 직접 투표(Hard Voting) 방식과 간접 투표(Soft Voting) 방식이 있다.
-직접 투표(Hard Voting) 방식은 분류 결과 중 다수결로 카테고리(Class)를 채택한다.
-간접 투표 방식은 분류 결과 중 가장 높은 확률값 하나를 카테고리로 채택한다. *
-회귀에서는 결과의 평균값을 채택한다.
# 배깅(Bagging)
Q. 배깅(Bagging)에 대해 옳은 것을 골라주세요.
-배깅은 전체 데이터를 분류기에 학습시킨다.
-배깅에서는 종류가 다른 분류기를 사용한다.
-배깅은 데이터를 샘플링하는 과정이 들어간다. *
-데이터를 샘플링할 때 데이터의 중복을 허용하는 방법을 페이스팅(Pasting)이라 한다.
# 랜덤 포레스트 (Random Forest)
Q. 올바른 랜덤 포레스트 방식을 골라주세요.
-Voting & Linear Patch & Decision Tree
-Voting & Random Patch & Naive Bayes
-Bagging & Random Patch & Decision Tree *
-Bagging & Linear Patch & Linear Regression
-Bagging & Random Patch & Naive Bayes
<클러스터링>
# 클러스터링 (Clustering)
Q. 클러스터링에 대해 올바르지 않은 것을 골라주세요.
-클러스터링은 비지도 학습으로 Label이 없다.
-클러스터링의 목표는 군집 내 분산을 최소화하는 것이다.
-군집 간 Bias를 최대화하면 클러스터링 성능을 높일 수 있다. *
-클러스터링은 정답이 없기 때문에 단순 정확도 등의 지표로 평가하기 어렵다.
# 클러스터링 알고리즘
Q. 클러스터링 알고리즘을 모두 고르세요.
-K-Means *
-SVM
-Naive Bayes
-GMM *
-KNN *
# K-Means 클러스터링
Q. K-Means 클러스터링에 대한 설명 중 올바르지 않은 것을 모두 고르세요.
-K-Means는 EM 알고리즘을 기반으로 수행된다.
-K-Means의 K는 클러스터의 개수를 의미한다.
-Expectation Step에서 각 군집의 중심 위치를 구한다.
-Maximization Step에서 군집 간 거리를 최대화한다. *
-K-Means 클러스터링에서 최초 중심점은 랜덤으로 선정될 수 있다.
-적절한 K의 개수는 데이터의 분포에 따라 항상 정해져 있다. *
# Gaussian Mixture Model
Q. Gaussian Mixture Model에 대해 올바른 것을 모두 고르세요.
-GMM은 전체 데이터의 분포가 여러 개의 정규분포 조합으로 이루어져 있다고 가정한다. *
-K-Means보다 계산량이 적어 대량의 데이터에 적용하기 좋다.
-데이터 분포의 형태가 원형이 아닌 경우에도 좋은 성능을 나타낸다. *
-GMM에도 Cluster Center 좌표가 존재한다.
# 계층적 클러스터링 (Hiarchical Clustering)
Q. 계층적 클러스터링 (HC)에 대해 올바르지 않은 것을 고르세요.
-계층적 클러스터링은 트리 형태의 구조인 덴드로그램을 가지고 있다.
-초기에 클러스터의 개수를 지정해주어야 한다. *
-클러스터링을 진행할 때 모든 유사도 측정 방식을 사용할 수 있다.
-데이터의 평균이나 분산을 구할 수 없을 때 사용할 수 있는 기법이다.
<차원 축소>
# 차원의 저주
Q. 차원의 저주에 관한 내용 중 틀린 것을 고르세요
-차원이 고차원이 될수록 저차원의 직관이 성립하지 않는다.
-저차원일수록 전체에서 데이터가 차지하는 공간이 매우 적어진다. *
-훈련 샘플이 엄청나게 많은 특성을 가지고 있을 때, 훈련이 느려진다.
-일정 차원을 넘으면 분류기의 성능이 점점 떨어져 0으로 수렴한다.
# 차원 축소
Q. 차원 축소에 대해 옳은 것을 모두 고르세요.
-관찰 대상들을 잘 설명할 수 있는 잠재 공간은 실제 관찰 공간보다 크다.
-차원 축소를 함으로써, 문제를 해결하기 더 어려워 진다.
-이미지에서 비슷한 패턴을 보이는 특징이 있다면 차원 축소의 대상이 된다. *
-관찰 공간 위의 샘플들에 기반으로 잠재 공간을 파악하는 것이다. *
# 주성분 분석(PCA)
Q. 다음 중 주성분 분석(PCA)의 순서 중 옳지 않은 것은?
-모든 데이터에서 각 행의 평균을 빼서 모든 행의 평균이 0이 되게 한다.
-원점을 지나는 직선 중에 데이터들을 정사영 했을 때의 분산을 최대로 하는 직선을 찾는다.
-각 점에서 직선까지의 거리 제곱의 합을 최대화 하는 것으로 직선을 찾는다. *
-이렇게 찾은 첫번째 주성분 벡터를 싱귤러(singular) 벡터라고 한다.
# CUR 분해
Q. CUR 분해에 대한 설명으로 틀린 것을 고르세요.
-C는 원래 행렬의 column을 샘플링한 행렬이다.
-column, row 샘플링은 uniform하게 수행한다. *
-column, row 샘플링은 복원 추출로 수행된다.
-CUR 분해 결과는 해석이 쉽게 가능하다.
# tSNE
Q. SNE, tSNE에 대한 설명으로 옳은 것을 고르세요.
-tSNE는 손실함수를 대칭 버전으로 변경하여 SNE의 단점을 보완한다. *
-tSNE는 정규분포를 사용한다.
-SNE는 저차원 공간의 데이터를 조건부 확률로 변환하여 고차원 공간에 데이터를 표시한다.
-SNE는 Cosine similarity를 사용하여 공간을 변화시킨다.
# 고차원에서 저차원으로 Visualization
Q. tSNE에 대한 설명으로 옳은 것을 고르세요.
-t-SNE 알고리즘은 모델 학습을 위한 데이터로 주로 사용된다.
-t-SNE 알고리즘은 주성분 축을 찾는 알고리즘으로 주성분 분석이라고도 부른다.
-t-SNE 알고리즘은 데이터 시각화를 위해 주로 활용되는 알고리즘이다. *
-t-SNE 알고리즘에서는 데이터 간의 거리가 완전히 그대로 보존된다.
<추천 시스템>
# 추천 알고리즘
Q. 다음 중 추천 알고리즘 접근법이 아닌 것은?
-Content-based
-Collaborative Filtering
-EM algorithm *
-Latent Factor Model
# Content based Recommendation
Q. 다음 중 Content based Recommendation에 대한 설명으로 올바르지 않은 것은?
-신규 item에 대한 추천이 가능하다.
-특이 취향 사용자에게도 맞춰 추천이 가능하다.
-다른 사용자의 rating 정보가 필요하다. *
-item의 feature를 추출하여 profile을 구성한다.
# Collaborative Filtering
Q. 다음 중 Collaborative Filtering에 대한 설명으로 올바르지 않은 것은?
-사용자에게 새로운 유형의 item을 추천해즐 수 있다.
-Cold Start Problem이 존재한다.
-신규 사용자 혹은 item에 대한 추천이 가능하다. *
-유사도 지표로 Pearson Correlation Coefficient를 사용할 수 있다.
# Latent Factor Model
Q. 다음 중 Latent Factor Model에 대한 설명으로 올바른 것은?
-사용자가 rating한 item들의 feature를 기반으로 추천한다.
-사용자와 item를 latent space 위로 mapping 후 Reconstruction하여 missing rating을 –추론한다. *
-다른 사용자의 rating 정보 없이 사용 가능하다.
-해석이 가능한 모델이다.
# 추천 알고리즘 평가
Q. 다음 중 추천 알고리즘 평가와 관련하여 옳지 않은 것은?
-입력 받은 rating 중 일부를 평가를 위해 사용한다.
-rating에 대한 오차로 평가 수행 시 모든 rating에 대한 정확도가 균일하게 높은 것이 좋은 결과이다. *
-Rank에 대한 Correlation인 Spearman's Rank Correlation을 사용할 수 있다.
-추천한 item에 대하여 사용자가 구매를 수행하였는지 여부로도 평가가 가능하다.
<딥러닝 기초>
# 퍼셉트론의 성질
Q. 퍼셉트론에 대해 올바르지 않은 것을 모두 골라주세요.
-퍼셉트론은 생물의 Neuron을 모사하여 설계했다.
-하나의 퍼셉트론에는 하나의 입력만 들어갈 수 있다. *
-퍼셉트론은 선형 방정식으로 표현이 가능하다.
-퍼셉트론으로 모든 논리 연산 Gate를 분류 할 수 있다. *
# 퍼셉트론의 구조
Q. 퍼셉트론의 구성 요소가 맞는 것을 모두 골라주세요.
-입력 데이터 분포 (p(x))
-가중치 (Weight) *
-바이어스 (Bias) *
-활성화 함수 (Activation Function) *
# Multi-Layer Perceptron
Q. MLP에 대한 설명 중 올바르지 않은 것을 골라주세요.
-한 층에 퍼셉트론을 여러개를 나열해 사용하는 것도 MLP라고 부른다. *
-Input layer, Hidden Layer, Output Layer로 구성되어 있다.
-Hidden Layer가 3층 이상이 되면 DNN (Deep Neural Network)이라 한다
-Hidden Layer가 늘어날수록 학습에 사용되는 파라미터가 늘어난다.
# 활성화 함수
Q. 활성화 함수로 사용되는 것들을 모두 골라주세요.
-ReLU function *
-Sigmoid function *
-Step function *
-tanh function *
-cos function
# 인공신경망(ANN) 이해하기
Q. 다음 중 인공신경망(ANN)에 관한 설명 중 틀린 것을 고르세요.
-뇌의 학습방법을 수학적으로 모델링한 기계학습 알고리즘이다.
-편향(Bias)과 가중치(Weight)를 내적하여 선형결합하고 활성화(Activation)함수를 적용하여 다음 노드를 계산한다. *
-입력층, 히든층, 출력층으로 구성된다.
-각 뉴런의 출력은 직접 전달되는 정보에만 의존한다.
# 손실 함수(Loss function) 이해하기
Q. 손실 함수(Loss function)에 관한 설명 중 틀린 것을 고르세요.
-신경망에서 계산된 결과값과 실제 결과값 사이의 차이를 정의하는 함수이다.
-손실 함수를 최소화하는 parameter를 찾기 위해 SGD 등의 학습 알고리즘을 사용한다.
-회귀와 분류에서 각각 제곱 오차(Mean-squared error), 크로스 엔트로피(Cross entropy)를 사용한다.
-손실함수를 최대화 하는 것이다. *
# 역전파법(Back Propagation) 이해하기
Q. 역전파법(Back Propagation)에 관한 설명 중 틀린 것을 고르세요.
-계산그래프를 사용하여 노드, 엣지를 따라가면 계산하기 수월하다.
-합성함수를 미분할 때 Chain rule을 사용한다.
-다음 layer의 gradient 값들을 이용해 이전 layer의 gradient 값을 구할 수 있다.
-노드끼리 연관되어 있어 병렬 연산이 불가능하다. *
# 기울기 소실(Gradient Vanishing) 문제
Q. 기울기 소실(Gradient Vanishing) 문제에서 해당 함수에 대한 설명 중 틀린 것은?
-Sigmoid : 망이 깊어질수록 Gradient가 1/4 씩 더 증가한다. *
-ReLU : 최대값이 1보다 큰 값도 가능하기 때문에 학습이 빠르다는 장점이 있다.
-Leaky ReLU : 0보다 작은 경우 ReLU에서 신경이 죽어버리는 현상을 극복한다.
-Tanh : 함수값의 범위가 (-1, 1), 도함수의 최댓값이 1이 된다.
# 최적화 알고리즘 이해하기
Q. 최적화 알고리즘에 대한 설명 중 틀린 것을 고르세요.
-Momentum은 과거에 이동했던 방식을 기억하며 그 방향으로 관성을 주는 방법이다.
-AdaGrad(Adaptive Gradient)에서 적게 변화하는 변수들은 step size를 크게 하고, 많이 변화하는 변수들은 step size를 적게 한다.
-RMSProp은 Adagrad의 단점을 해결하기 위해 합을 지수평균으로 대체한 방법이다.
-Adam(Adaptive Moment Estimation)은 Momentum과 Adagrad를 합친 방법이다. *
<자연어 처리>
# Count-based Representation 방법
Q. Count-based Representation 방법에 대해 적절하지 않은 것을 고르시오.
-비정형 데이터를 정형데이터로 바꾸는 작업이다.
-본 방법을 실행하기 전 Stop Wording을 진행한다.
-표현된 Vector는 discrete space에 존재한다.
-Binary / Frequency representation 방법 2가지가 존재한다.
-Document를 표현하는 가장 쉬운 방법으로 텍스트가 word의 순서를 고려하는 Vector로 표현된다. *
# TF-IDF
Q. TF-IDF에 대한 설명 중 적절하지 않은 것을 고르시오.
-Term Frequency와 Inverse Document Frequency의 곱으로 이루어져 있다.
-TF는 빈도가 높을수록 Weighting이 높아지게 된다.
-DF는 빈도가 높을수록 Weighting이 높아지게 된다. *
-각 단어들이 Feature가 된다.
-TDM과 마찬가지로 단어의 순서가 고려되지 않는다.