 딥러닝에서의 학습이란? 신경망의 목표는?
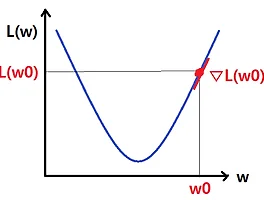
# 딥러닝에서의 학습이란? 위 그림에서, 각 노드에 들어온 1, x1, x2, ...의 값에 대해 각 노드에 할당된 bias와 weight 매개변수들을 선형 결합한 값을 활성화 함수 f1, f2, ...에 넣어 나온 값 z1, z2, ...를 다시 다음 노드에 전달해서 같은 과정을 반복한다. 최종 output 값, 즉 예측한 값이 나오게 되면 실제값과 얼마나 차이가 나는지를 loss function을 이용해 계산하고(그렇다고 해서 "loss function = 실제값-예측값"은 아니다. 여러 loss function이 있다), 그 '틀린 정도'의 gradient(즉 loss function의 gradient)를 다시 앞쪽 노드로 backpropagation을 활용해 그대로 보존하면서 전달한다. 이 전달된..
딥러닝에서의 학습이란? 신경망의 목표는?
# 딥러닝에서의 학습이란? 위 그림에서, 각 노드에 들어온 1, x1, x2, ...의 값에 대해 각 노드에 할당된 bias와 weight 매개변수들을 선형 결합한 값을 활성화 함수 f1, f2, ...에 넣어 나온 값 z1, z2, ...를 다시 다음 노드에 전달해서 같은 과정을 반복한다. 최종 output 값, 즉 예측한 값이 나오게 되면 실제값과 얼마나 차이가 나는지를 loss function을 이용해 계산하고(그렇다고 해서 "loss function = 실제값-예측값"은 아니다. 여러 loss function이 있다), 그 '틀린 정도'의 gradient(즉 loss function의 gradient)를 다시 앞쪽 노드로 backpropagation을 활용해 그대로 보존하면서 전달한다. 이 전달된..





