VDSR은 다음과 같이 한 문장으로 말할 수 있겠습니다. "깊은 CNN 구조, residual learning, 높은 학습률, 여러 scale factor에 대한 훈련을 통해 기존 SR 기술들보다 속도와 성능 면에서 훨씬 월등함을 보여준 모델이다."
~ Accurate Image Super-Resolution Using Very Deep Convolutional Networks ~
# 1. Introduction

처음에는 SISR(single image super-resolution), 즉 단일 이미지 초해상화를 위해 기존에 쓰였던 방법들을 간단히 언급합니다. 그리고 SRCNN에 대해서 더 자세히 얘기합니다. SRCNN에서 쓰인 CNN은 LR(Low Resolution, 저해상도 이미지)를 HR(High Resolution, 고해상도 이미지)로 한번에(end-to-end) 변환할 수 있습니다. 그래서 SRCNN은 별도의 특성 공학(feature engineering) 과정이 필요없다고 합니다. 그러나 SRCNN에는 세가지 한계점이 있습니다.
1) 조그만 이미지 영역의 문맥에 의존한다.
: 만약 큰 scale factor를 쓴다고 할 때, 초해상화에 쓸 작은 이미지 패치(SRCNN이 원본에서 패치를 서브 샘플링하고 그걸 이용한 것) 안에 들어있는 정보로는 원래 HR 이미지의 자세한 사항들을 복원하기 힘들다는 점입니다. 즉, LR에 적용되는 receptive field 크기가 작으면 그만큼 정보를 못받아들이기 때문에, HR로 정확하게 초해상화시키기 힘들다는 것입니다. 연구에서는 이것을 모델을 깊게 만듦으로써 receptive field의 크기를 키워 해결했습니다. 뒤에서 더 자세히 알아보겠습니다.
2) 훈련이 너무 천천히 수렴된다.
: 기존 SRCNN은 학습률(learning rate)이 작아 훈련 수렴 속도가 느린데, 만약 이 연구처럼 깊은 모델을 사용한다면 수렴 속도는 더욱 느릴 것입니다. 느린 수렴 속도를 해결하기 위해 매우 높은 학습률을 사용했는데, 이로 인한 그래디언트 소실/폭주(vanishing/exploding) 문제는 residual learning과 gradient clipping으로 해결했습니다.
3) 단일 scale에 대해서만 네트워크가 작동한다.
: 기존 SRCNN은 하나의 모델에 대해 하나의 scale factor만 처리 가능해서, 새로운 scale이 필요한 경우 모델을 새로 학습해야했습니다. 그러나 VDSR은 비록 단일 모델(single network)이지만 하나로 정해진 scale factor만을 처리하지 않고(ex. SRCNN과 나중에 소개할 ESPCN에선 scale facor=3으로 정해져있음), 다양한 크기(multiple)의 scale factor를 처리할 수 있습니다. 이를 위해 multiple scale factor로 (x2, x3, x4) 훈련하였으며, 단일 scale factor로만 훈련한 모델보다 성능이 좋았습니다.
# 2. Related Work
딥러닝을 이용한 SR 방법 중 SOTA 모델이 SRCNN이므로, 여기서는 SRCNN과 본 연구에서 제안한 모델인 VDSR을 비교합니다.
SRCNN은 필터 크기가 9, 1, 5인 레이어를 써서 총 3층이지만, 본 연구에서는 필터 크기가 3인 레이어만 써서 총 20층을 만드는데 성공했고, 그 덕분에 reconstruct를 위해 필요한 정보의 크기가 41x41로 더 커졌습니다. 즉, receptive field의 크기가 SRCNN은 13x13인 반면, 본 연구에선 41x41이 된 것이며, 이것이 더 넓은 영역에서의 문맥을 파악할 수 있게 해준 것이라고 할 수 있습니다. 즉, SRCNN에서 주장한 바와 다르게, 깊은 모델은 성능을 크게 증가시킨다고 할 수 있습니다.
이 연구에선 SRCNN을 통해 만들어진 고화질 데이터, 즉 HR 이미지는 low frequecny information(LR 이미지) + high frequecny information(잔여 이미지 or 이미지의 더 자세한 부분)으로 나눌 수 있다고 봅니다. 그래서 인풋 이미지(LR)와 아웃풋 이미지(HR)는 같은 low freq. inform.을 가진다, 즉, 둘다 LR 이미지의 정보를 가지고 있습니다. (인풋은 그 자체가 LR 이미지이므로 당연하고, 아웃풋은 LR+residual이므로 그렇습니다.)
그래서 SRCNN은 두가지 목적을 수행한다고 볼 수 있습니다. 인풋(LR) 자체를 모델 끝으로 보내기 + 아웃풋(HR)을 만드는데 필요한 residual을 만들기(reconstruct). 인풋을 모델 끝으로 보내는 행위는 오토인코더와 비슷하다고 볼 수 있는데, 훈련 시간이 이 오토인코더 부분을 배우는데 쓰이기 때문에, image detail, 즉 residual, 다시 말하면 HR 이미지를 생성하는데 필요한 나머지 부분을 배우기 위한 수렴률이 떨어집니다. 이것은 곧 전체 모델 학습 수렴 속도가 느려진다는 것과 같습니다. 그러나 이 연구에서 제안한 VDSR은 이 residual 부분을 바로(directly) 모델링함으로써, 더 좋은 정확도를 더 빠르게 얻을 수 있습니다.
그리고 SRCNN은 하나의 scale factor에 대해서만 훈련되고, 훈련된 SRCNN은 오직 훈련 때 사용되었던, 구체적인 scale factor에서 동작해야합니다. 그 말은 즉슨, 만약 새로운 scale factor가 요구된다면, 아예 새로운 모델이 훈련되어야하며, 다양한 크기의 scale factor를 적용하기 위해선 그때마다 각각의 새로운 모델을 훈련해야 합니다.
그러나 여러분의 생각대로, 각각의 단일 scale factor에 대해 각기 다른 모델을 훈련하는 것은 비효율적입니다. 그래서 VDSR은 여러(multiple) scale factor로 초해상화를 할 수 있게 됩니다. 실험은 x2, x3, x4의 scale factor에 대해 진행되었습니다.
이밖에도 사소한 차이점이 있습니다. VDSR은 들어온 인풋에 대해 모델 훈련 동안 각 레이어가 제로 패딩을 해줌으로써 아웃풋과 그 사이즈가 같습니다. SRCNN은 그렇지 않아서 인풋보다 아웃풋 사이즈가 작았습니다. 그리고 SRCNN은 각 레이어마다 다른 학습률을 사용했지만, VDSR은 간단하게 모든 레이어에 같은 학습률을 적용했습니다.
# 3. Proposed Method
- 제안된 모델 -
인풋 이미지가 들어오는 첫번째 레이어와 이미지 reconstruct를 위한 마지막 레이어를 제외한 나머지 레이어들은 3x3 커널, 64 채널의 Conv 레이어들이다. 이전 연구들처럼 인풋을 YCbCr로 바꾸고 SR 알고리즘은 Y채널에만 적용합니다. 따라서 인풋 레이어의 인풋 채널과 아웃풋 레이어의 아웃풋 채널은 모두 1입니다.
이 논문에선 인풋으로 LR을 넣는게 아니라 (bicubic) interpolation을 한 LR, 즉 ILR(interpolated low-resolution)을 넣는다고 SRCNN 논문보다 정확히 설명하고 있습니다. 또한, LR이 모델을 통과한 결과물을 바로 아웃풋이라고 하는게 아니라 일단 그건 residual(=이미지의 더 자세한 부분)이고, 그 residual에 인풋 ILR을 한번 더한 것을 아웃풋이라고 합니다. 아웃풋은 엄연히 말하면 HR은 아니고, HR에 가까워야 하는 desired image입니다.
깊은 신경망의 문제점 중 하나는 이미지가 컨볼루션을 통과할수록 feature map 사이즈가 작아진다는 것인데, 그로 인해 계속해서 가장자리 픽셀이 날아갑니다. 그런데 만약 의미있는 정보를 뽑기 위해 필요한 영역의 크기가 큰 경우, 가장자리 픽셀들도 중요해질 수 있습니다. 이 연구에선 그런 문제를 해결하기 위해, feature map이 컨볼루션을 통과하기 전에 제로 패딩을 해주었습니다.
- 훈련 -
* Residual Learning
연구의 목표는 들어온 ILR 이미지 x를 HR 이미지로 가장 잘 근사시키는 함수(모델) f를 찾는 것이고, 이 근사된 HR 이미지, 즉 desired image인 y_hat = f(x)와 실제 정답 HR 이미지 y간의 차이를 최소화시키는 것입니다. 구체적으로는 손실 함수 MSE를 최소화하는 것입니다.
SRCNN에서는 인풋 그 자체가 아웃풋 레이어 도달 전까지 쭉 통과되었습니다. 한편 이 연구처럼 많은 레이어가 있는 경우엔, (그냥 깊은 모델에서 발생하는 흔한 문제인) 그래디언트 소멸/폭주 문제가 일어날 수 있습니다. 그런데 연구에서 제한한 residual learning을 사용하면 그러한 문제가 간단히 해결됩니다.
ILR에서 HR(= y)을 바로 예측(= f(x))하기보다는 residual(= r = y-x), 즉 image detail을 예측합니다. 이때 이 r은 0이거나 작은 값입니다. 그래서 바로 HR을 예측하는 것보다 r을 예측하는게 모델에게 더 편합니다. 위에서도 설명했듯이, 우리가 만들 이미지 f(x)는 high freq. inform. + low freq. inform.이기 때문에 f(x)는 x와 거의 비슷하거나 같기 때문입니다. 즉, residual learning을 통해 SISR 문제를 좀 더 쉬운 문제로 치환했습니다. 그렇기 때문에 MSE도 y와 f(x) 사이가 아니라 r과 f(x) 사이를 측정하게 됩니다. 기존 MSE와 바뀐 MSE의 수식은 아래와 같습니다.
* High Learning Rates for Very Deep Networks / Adjustable Gradient Clipping
SRCNN과 다르게 높은 학습률을 적용해서 수렴 속도를 빠르게 만들었는데, 단순히 높은 학습률을 적용하면 그래디언트 소실/폭주 문제가 일어날 수 있으므로 gradient clipping을 했습니다. gradient clipping은 그래디언트가 미리 정의한 특정 범위 안의 값만 갖도록 제한하는 것입니다. 연구에서 제안한 그래디언트 범위는 아래와 같습니다.

즉, 현재의 학습률 γ에 따른 범위 안의 그래디언트만 사용할 수 있도록 제한(clipping)했고, 그 결과 SRCNN보다 더 빠르게 수렴했습니다. 뒤의 설명을 참고하면 20에폭마다 학습률이 10배씩 줄어드는데, 그만큼 그래디언트의 범위는 늘어나게 됩니다. 즉, 학습이 진행될수록 gradient clipping이 덜 엄격하게 적용되는데, 이유는 학습률이 점점 줄어들수록 효과적인 그래디언트 값은 0에 가까워지며, 더 효과적인 그래디언트 값을 찾기 위해 많은 이터레이션이 반복되기 때문입니다.
쉽게 말하면, gradient clipping의 목적은 높은 학습률로 인한 그래디언트 소실/폭주 문제를 막기 위함인데, 훈련이 진행될수록 학습률은 감소해 그래디언트 폭주 가능성은 점점 줄어듭니다. 그런데 만약 쓸 수 있는 그래디언트 값이 이전처럼 강하게 한정되어 있으면 더 적절한 그래디언트 값을 찾기 위해 훈련에 더 많은 시간이 소요될 수 있으므로, 학습률이 감소함에 따라 쓸 수 있는 그래디언트 값을 더 많이 제공해주는 것입니다.
gradient clipping을 한 결과 모델의 수렴 속도는 아주 빨라졌는데, 3층의 SRCNN의 훈련 속도는 며칠이 걸린 반면, 20층의 VDSR은 4시간밖에 걸리지 않았습니다. (기준이 상세하지 않지만, 아마 같은 성능을 내는데까지 걸린 시간일 듯합니다.)
(* 결국 그래디언트 소실/폭주 문제를 해결하는데 residual learning과 gradient clipping이 도움이 됩니다.)
* Multi Scale
일반적으로, 하나의 네트워크는 하나의 scale factor를 위해 만들어집니다. 그러나 VDSR은 multi-scale 모델인데, 말그대로 여러 개의 scale factor에 대해 훈련이 된 것입니다. 이때, multi scale로 모델을 훈련하는 것은 간단합니다. 훈련할 때 사용하는 데이터의 구성을, 각각의 구체적인 scale factor가 적용된 LR 이미지들의 하나의 큰 집합으로 만드는 것입니다. 당연히 그에 대한 정답, 즉 label 데이터인 HR 이미지도 존재할 것입니다.
즉, 아마 코드 상에서는 SRCNN이나 ESPCN과 같이, 모델 train 코드 상에서 따로 scale factor를 정하는 부분은 없을 것입니다. 실제로 스타를 가장 많이 받은 VDSR 파이토치 구현 깃허브(https://github.com/twtygqyy/pytorch-vdsr)를 보면, 모델 train 코드에는 args parser 등으로 scale factor를 정하는 부분이 없는 것을 확인할 수 있었습니다. 아마 훈련용 데이터셋인 .h5 파일 안에 논문에서 제시하는 데이터 셋 구성대로 구성되어 있을 것 같습니다. 한편 해당 깃허브를 제외한 나머지 VDSR 구현 깃허브에서는 대부분 multi scale factor 학습은 안 하는걸로 가정하고 구현한 것 같습니다.
데이터 준비는 SRCNN과 비슷한데 약간 다릅니다. 즉 인풋을 YCbCr로 바꾸고 Y채널만 이용하는건 같습니다. 근데 패치 사이즈를 receptive field 크기로, 즉 41x41로 이용합니다.
# 4. Understanding Properties
이 섹션에서는 논문에서 제안한 large depth, residual learning, multi scale network에 대해서 실험합니다.
- The Deeper, the Better -

레이어를 많이 쌓는것은 필터들을 전역적으로 리딩(leading)하는 것입니다. 즉, 필터가 더욱 커진 픽셀 공간에 반응할 수 있도록 해주는 것입니다. 보통 receptive field라는건 필터 사이즈를 말합니다. 에를 들어 3x3 필터 1개를 쓰면 receptive field 크기는 3x3이다. 그리고 3x3 필터를 두개 쓰면 5x5와 효과가 같아집니다. 그럼 receptive field 크기는 5x5입니다.
이 논문에선 첫번째와 마지막 레이어를 제외한 나머지 레이어에서 3x3 크기의 필터를 사용합니다. 그러할 때 깊이가 D인 네트워크의 receptive field 사이즈는 (2D+1)x(2D+1) 이라고 합니다. 공식을 봐도, D=2이면 3x3 필터가 두개라는건데, 그때 recptive field 크기는 위에서 말한 것처럼 5x5가 됩니다. 이는 VGG 논문에서 그 증거를 확인할 수 있습니다.
이 모델의 층이 20개니까 D=20이고, 그래서 아까 언급한 것과 같이, 최종 receptive field 크기가 41x41이라고 되어있습니다. 결론적으로, 모델의 깊이가 깊어지면 receptive field 크기가 커지므로 더 넓은 이미지 영역에서의 문맥을 파악할 수 있게 됩니다. 게다가, 비선형적인 특징을 갖는 컨볼루션 레이어가 많이 쌓인게 깊은 네트워크이므로, VDSR은 고수준의 비선형성을 사용할 수 있게 되는 것도 장점입니다.
위 그래프와 같이, 각 scale factor에서 깊이가 깊어질수록 모델의 성능(PSNR)이 높아지는 것을 확인할 수 있습니다.
- Residual Learning -
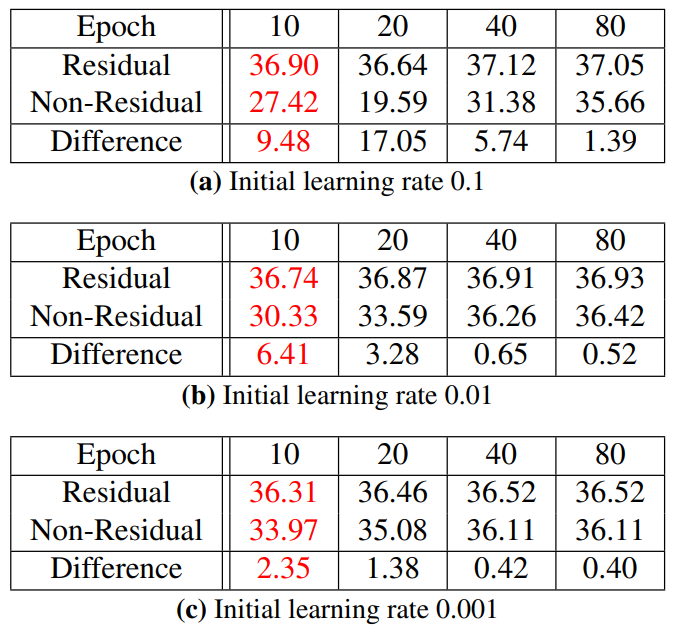
residual learning에 대해선 위에서 충분히 설명했고, 여기선 별다른 내용이 없습니다. 요약하면, residual 네트워크는 non-residual 네트워크보다 더 빠르게 수렴하고, 수렴했을 때 성능도 훨씬 좋습니다. 위 표를 보면 알 수 있습니다.
- Single Model for Multiple Scales -

각기 다른 스케일에 따른 많은 SR 과정은 이 연구에서 제안한 multi-scale 모델에서 이루어질 수 있는데, 이는 single sclae factor만으로 이루어진 모델들이 합쳐진 것보다 더 작은 용량입니다. 즉, 논문에서 'single-scale machines combined'라는 것은 하나의 scale factor로만 훈련된 여러 모델들이 합쳐진 형태를 의미하는 듯합니다.
그러나 논문의 'multi-scale machine'은 여러 scale factor에 대해 학습이 되어있으므로 single-scale 모델 3가지 합친 것보다 우리 multi-scale 모델 1개가 용량도 적고 더 낫다는 뜻인것 같습니다.
위 표를 보면, 단일 스케일로 학습이 된 모델은 테스트할 때 같은 스케일이 아니면 성능이 안좋습니다. 오직 같은 스케일로 테스트해야 성능이 좋습니다. (ex. x2로 학습된 모델은 x2로 테스트할 때만 좋고 x3, x4로 테스트할 때는 좋지 않습니다.) 그러나 여러 스케일, 특히 테스트 대상 3개의 스케일 모두로 학습된 모델은 어떤 스케일로 테스트를 해도 모두 성능이 좋습니다.

위 사진의 윗 부분들은 multi scale로 훈련된, VDSR로 각 scale factor에 대해 실험한 것이고, 아랫 부분들은 single scale(x3)으로 훈련된, SRCNN으로 각 scale factor에 대해 실험한 것입니다. 당연하게도, 여러 scale factor로 훈련된 VDSR이 하나의 scale factor로만 훈련된 SRCNN보다 각기 다른 scale factor에 대해서도 성능이 좋은 것을 확인할 수 있습니다.
결론적으로, SR 모델은 여러 개의 scale factor로 훈련되어야 성능이 더 좋아진다는 것이 입증되었습니다.
원 논문
: https://arxiv.org/pdf/1511.04587.pdf
참고 사이트
구현 코드
: https://github.com/jhcha08/Implementation_DeepLearningPaper/blob/master/SR.%20VDSR.ipynb
* 코드 구현 시 주의점 *
레이어가 반복되는 것을 구현하기 위해 __init__에 레이어 하나만 self.conv1 = ConvBlock(~~) 이렇게 정의 후 forward에서는 for _ in range(18) : x = self.conv1(x) 이런식으로 했었는데, 파라미터 수를 model.summary로 측정했을 때와 total_params = sum(p.numel() for p in model.parameters()) 으로 측정했을 때가 달랐다. 이유는 처음에 __init__에 저렇게 하나의 레이어만 정의하고 반복해서 사용하면 "파라미터가 공유"되기 때문에 실제 파라미터 수를 잴 때는 반복되는 레이어를 고려하지 않는다. 따라서 원래 목적에 맞게 하려면 __init__에 각기 다른 conv를 정의해두고 forward에서 연결시키거나, 한 종류의 conv를 정의하고 반복해서 사용하되 Sequential로 묶는 등의 기법이 필요하다. 자세한 것은 코드 참고. 한편 그렇다는 것은 만약 파라미터를 공유하기 위한 네트워크가 필요할 때, 위 방법을 쓸 수도 있다는 것이다. (ex. 발전된 LapSRN, SESR 구현)
'딥러닝 & 머신러닝 > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Super Resolution - MSRN (ECCV 2018) (0) | 2021.07.19 |
|---|---|
| [논문 리뷰] Super Resolution - ESPCN (CVPR 2016) (0) | 2021.06.18 |
| [논문 리뷰] Super Resolution - SRCNN (ECCV 2014) (0) | 2021.06.17 |
| [논문 리뷰] GAN - CatGAN (ICLR 2016) (0) | 2020.04.28 |
| [논문 리뷰] GAN - cGAN (arxiv 2014) (0) | 2020.04.19 |



