ESPCN은 다음과 같이 한 문장으로 말할 수 있겠습니다. "기존 SR 기법들처럼 모델의 첫 부분 혹은 전처리 부분에서 LR 이미지를 upsampling 하는 것이 아니라, efficient sub-pixel convolution layer를 사용해 모델의 끝에서 upsampling함으로써 모델의 연산량과 파라미터 수를 줄이고 성능도 높인 모델이다."
~ Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network ~
# 1. Introduction
SR(Super resolution, 초해상화)은 기본적으로 LR(Low Resolution, 저해상도) 이미지가 HR(High Resolution, 고해상도) 이미지의 blurred된 버전이라는 것을 가정합니다. SR은 정답이 없는(ill-posed) 문제인데, 이유는 다음과 같습니다. 첫째, HR이 LR로 바뀌고 샘플링 되는 과정 중 HR의 정보가 손실됩니다. 그리고 이 과정은 역과정이 없기에, 손실된 정보를 찾을 방법이 없기 때문입니다. 둘째, 초해상화는 LR을 HR로 바꾸는 문제인데, HR의 후보는 여러가지가 있을 수 있기 때문입니다.
SR 기술은 HR 데이터의 많은 정보는 대부분 쓸모없다고 가정합니다. 그래서 LR의 요소로부터 HR을 정확하게 복구될 수 있다고 생각합니다. 따라서 SR은 결국 추론 문제입니다. SISR(single image super-resolution)은 잃어버린 HR 정보를 하나의 LR 이미지로부터 복구하기위해, 원본 데이터에 존재하는 '암시적 중복성(implicit redundancy)'을 학습하려는 기술입니다.
- Related Work -
SISR 문제를 해결하기 위한 다양한 방법들이 있습니다. 여기서는 edge-based, image statistics-based, patch-based, sparsity-based, auto-encoder, predictive convolutional sparse coding(SRCNN), TNRD, LISTA, random forest 등을 소개합니다.
- Motivations and Contributions -
기존에 LR을 HR로 바꾸는 과정은 다음과 같은 순서로 진행됩니다. SRCNN과 VDSR이 이와 같은 방법을 사용합니다.
1) bicubic interpolation을 사용해 HR의 해상도를 낮춰 LR을 만듭니다. 여기서 해상도가 한번 줄어듭니다.
2) 해상도를 낮춘 LR을 다시 bicubic interpolation을 통한 upscaling으로 HR과 같은 해상도(∽크기)를 가진 (HR)'를 만듭니다. (여기서 '같은 해상도'를 갖게 한다는건 원본인 HR로 복원한다는게 아니라, HR과 크기를 맞춰준다는 뜻으로 이해하는게 좋은 것 같습니다.)
3) (HR)'을 통하여 HR을 예측하는 모델을 형성합니다.
이처럼 일반적인 초해상화 기법에서는 본격적으로 진짜 HR에 가까운 (HR)'을 만들기전에, 전처리 과정이나 네트워크의 첫 단계에서 LR을 미리 HR과 같은 해상도(∽크기)로 만드는 upscaling 과정이 들어갑니다. 그러나 이 같은 과정에는 두가지 단점이 있습니다.
1) 첫 단계에서 upscaling을 해버리면, upscaling되서 커져버린 이미지가 컨볼루션을 통과하면서 연산량이 커져버리고, 결국 속도가 느려집니다.
2) upscaling을 위해 bicubic interpolation 같은 interpolation 방법을 써야 하는데, 이는 원본 정보를 reconstruct 하기 위한 정보를 가져오지 않아 큰 도움이 되지 않습니다.
그래서 논문에서 제안하는 방법은 모델 첫 단계가 아닌, 끝 단계에서 LR에서 (HR)'로 바꾸는 것이고, LR feature map을 (HR)'로 점점 초해상화시키는 것입니다. 모델 끝 단계에서 초해상화가 이루어진다는 것은, 곧 LR이 바로 모델에 들어간다는 뜻입니다.
즉, 초반의 bicubic interpolation을 이용한 upscaling 같은 과정이 필요 없어집니다. 그러므로 첫 단계에서 upscaling된 feature map을 여러 컨볼루션 레이어에 통과시킬 필요없이, 끝에서만 upscaling이 이루어지므로 연산량이 줄어듭니다. 이 논문에선 끝에서만 upscaling을 하는 레이어 "efficient sub-pixel convolution layer"를 제안합니다. 이러한 특징들의 구체적인 장점들로 다음 두가지가 있습니다.
1) upscaling, 즉 본격적인 HR을 만들기 전에 먼저 HR의 해상도(∽크기)에 맞도록 하는 작업이 모델의 끝에서 이루어짐으로써, LR이 모델에 바로 들어가게 됩니다. 그 덕에 특징 추출이 기존처럼 HR 공간이 아닌, LR 공간에서 컨볼루션을 통해 이루어지며, 이는 계산의 복잡성을 감소시킵니다. 애초에 저해상도의 인풋이 들어가기 때문에, 필터 크기를 더 작게해서 사용할 수 있고, 비슷한 맥락의 정보들을 합칠 수 있습니다. 이는 계산량과 복잡도를 감소시키는 효과가 있습니다.
2) 기존에는 인풋 이미지에 대해 하나의 upscaling 필터만을 썼는데, 여기서는 레이어가 L개일 때, n_L-1개의 feature map에 n_L-1개의 upscaling 필터를 씁니다. 그리고 upscaling시에 bicubic interpolation 같은 interpolation을 쓰지 않는데, 이건 결국 모델이 (필터가 포함된) 레이어 통과를 통해 SR에 필요한 전처리 과정을 암시적으로 배운다는 걸 뜻합니다. 따라서, 네트워크는 별도의 interpolation 없이도 더 정교하게 LR에서 HR로 바꾸는 법을 배울 수 있게 됩니다.
# 2. Method
SISR이 하는 건 원래 HR 이미지 I_HR에서 다운스케일링된 LR 이미지 I_LR로부터 최대한 원본 HR 이미지에 가까운 I_SR을 추론하는 것입니다. r을 upscaling factor라고 할 때, I_LR을 만들기 위해서 I_HR을 먼저 가우시안 필터를 통과시키고, r배로 downscaling 합니다. I_LR과 I_HR이 각각 C개의 채널을 가지고 있다하고, I_LR(원본)의 텐서 사이즈는 H x W x C이라고 할 때, I_HR의 텐서 사이즈(가로 세로가 r배만큼 늘어난, SR된 텐서)는 rH x rW x C이 됩니다.
이제 LR 이미지인 I_LR을 모델의 마지막 레이어 전까지 통과시킵니다. 그러면 컨볼루션 레이어들을 통과하면서 LR feature map이 형성됩니다. 그리고 마지막에 sub-pixel convolution layer를 통과시켜 LR feature map을 upscaling해 I_SR을 만듭니다. 이를 수식으로 나타내면 아래와 같습니다. 수식에서 W_l, b_l, l ∈ (1, L-1) 입니다.

자세히 보면 평범한 컨볼루션 과정인 것을 알 수 있습니다. 인풋 이미지 I_LR이 컨볼루션 층(W_1)을 거치고, 크기에 맞는 bias가 더해진 후, activation func.을 지나 f_1이 되고, 이 과정이 반복되는 것입니다. 위에서 언급한 변수들의 범위를 보면 l이 L-1까지만 있는걸 볼 수 있는데, 마지막 레이어 f_L는 지금까지 컨볼루션을 통과하며 만들어진 feature map을 추론된 HR인 I_SR로 만듭니다. 이는 조금 이따가 설명할 수식에 나옵니다.
한편 l번째 레이어의 파라미터 수는 n_l-1 x n_l x k_l x k_l 입니다. 이때 n_l-1 = 인풋 feature map 채널 수(그래서 n_0 = C), n_l = 아웃풋 feature map 채널 수, k_l x k_l = 커널 사이즈입니다.
- Deconvolution layer -
deconvolution은 convolution과 작동 방식은 비슷하지만 이와 반대로 feature map 크기를 증가시킵니다. 먼저 각 픽셀 주위에 zero padding을 추가하고, padding을 추가한 것에 컨볼루션 연산을 진행합니다. SRCNN에 적용된 bicubic interpolation도 이 deconvolution을 통한 upscaling 방식의 특별한 경우입니다. 그러나 저자들은 이 방식이 아닌 새로운 방식을 제안합니다.
- Efficient sub-pixel convolution layer -
원본 이미지가 H x W 사이즈였다면, r배로 업스케일링된 이미지는 rH x rW 사이즈가 됩니다. 그래서 마지막 레이어인 efficient sub-pixel convolution layer는 LR보다 r^2만큼 채널 수(feature map 개수)를 늘린 다음, 그 feature map을 순서대로 조합해서 HR 이미지를 만들어냅니다. 인풋으로 들어온 LR 이미지(I_LR)의 채널이 1, 즉 이미지가 1개이므로, 최종 결과인 HR 이미지(I_SR) 또한 채널이 1, 이미지 1개입니다.
그리고 r^2배만큼 늘어난 feature map 각각에서 한 픽셀씩 떼와서 순서대로 조합해 HR 이미지로 reconstruct 합니다. 예를 들어 보라색 feature map이 49개인데, 자세히 보시면 HR 이미지에서 보라색 픽셀이 49개입니다. 순서대로 조합은 파이토치 기준 nn.PixelShuffle이라는 레이어를 통해 할 수 있습니다.
위 수식은 아까 설명드린다고 했던 마지막 레이어의 동작을 설명하는 수식입니다. 여기서 PS 함수는 periodic shuffling을 나타냅니다. PS 함수는 r^2개의 HxWxC feature map들(저해상도)을 1개의 rH x rW x C feature map(고해상도)으로 만듭니다.
직관적으로 그림만 보자면, LR 이미지가 upscaling 되면서 좀더 촘촘한 픽셀들로 재구성되어 HR 이미지로 나타납니다. 이때, 위 그림에서는 C=1이지만, 인풋 이미지가 RGB 3채널이면 C=3이 되는거고 그에 따라 HR 이미지도 RGB 3채널이 됩니다.

위 수식은 실제 HR 이미지인 I_HR과 모델이 예측한 HR 이미지인 f_L(I_LR) 간의 차이를 계산하는 목적 함수입니다. 기본 형태는 MSE를 따르며, 각 픽셀 하나하나의 차이를 고려합니다.
이러한 efficient sub-pixel convolution layer를 적용하면 deconvolution 레이어보다 log2(r^2) 시간만큼 빠르게, 다른 업스케일링 기법들보다 r^2시간만큼 빠르게 동작한다고 합니다.
# 3. Experiments
훈련용 데이터 셋으로는 91개의 이미지(91-images)와 ImageNet이 사용되었으며, 테스트 데이터 셋으로는 Set5, Set14, BSD300, BSD500이 쓰였습니다. 비디오 데이터에 대해서도 실험했는데, 이는 따로 언급하지 않겠습니다.
모델 레이어 수는 3, (f=필터 사이즈, n=feature map 수)라고 할 때, (f1, n1) = (5,64), (f2, n2) = (3, 32), f3 = 3, 활성화 함수는 tanh입니다. 이때 마지막 레이어엔 활성화 함수를 적용하지 않습니다.
이전 SR 관련 연구와 마찬가지로, 원본 HR을 그대로 정답 데이터로 쓰는게 아니라, 일정 크기로 sub-sampling해서 씁니다. 또한 이전 SR 관련 연구와 마찬가지로, 인풋 LR 이미지를 YCbCr로 이미지를 변환시킨 후 Y채널, 즉 휘도만 고려해서 실험을 진행했습니다. (이는 ESPCN 그림에서 인풋과 아웃풋 채널이 각각 1인 이유이기도 합니다) upscaling factor는 3을 사용하였습니다.
정답 데이터, 인풋 데이터가 될 sub-image들은 모두 크기가 17r x 17r이며, sub-image로 뽑힐 때 원본에 적용될 스트라이드는 I_HR에 대해 (17 − Σmod (f, 2)) × r, I_LR에 대해 (17 − Σmod (f, 2))입니다.
(Σmod(f,2)를 계산해보면 = mod(f1,2) + mod(f2,2) + mod(f3,2) = mod(5,2) + mod(3,2) + mod(3,2) = 1+1+1 = 3인데, 구현 코드 상에서는 이를 고려한 부분을 볼 수 없었습니다. 구현이 잘못된건지, 제가 생각을 잘못하고 있는건지 모르겠습니다.)
- Benefits of the sub-pixel convolution layer -

표를 보면, 91개의 이미지 셋으로 훈련했을 때는 ESPCN이 SRCNN보다 살짝 좋고(0.01단위), relu를 적용했을 때는 오히려 SRCNN보다 ESPCN의 성능이 더 떨어지는 것을 확인할 수 있습니다. 그러나 ImageNet으로 훈련했을 때는 relu를 적용한 ESPCN이 그렇지않은 SRCNN보다 성능이 더욱(0.1단위) 좋아지는 것을 확인할 수 있습니다.
- Comparison to the state-of-the-art -
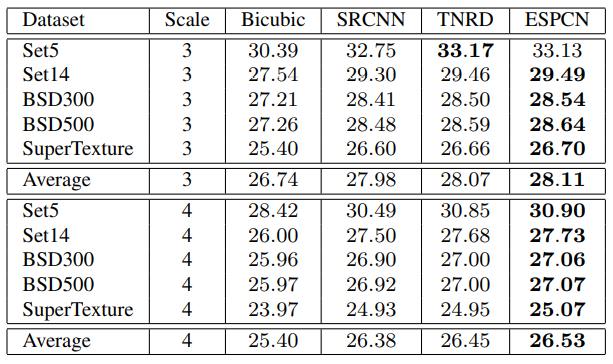

표와 예시 이미지들을 보면, ESPCN은 기존 SR 모델들보다 수치적으로나 시각적으로나 우수한 성능을 보입니다.
- Run time evaluations -
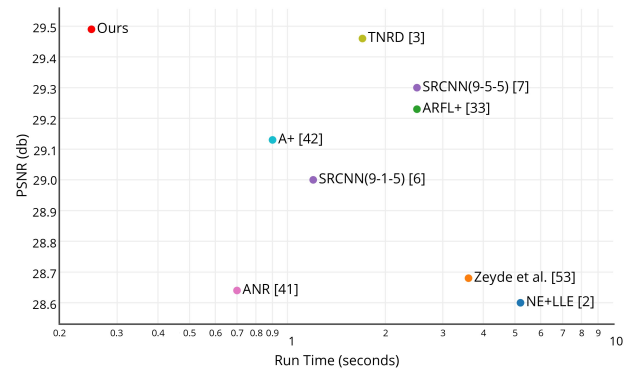
다른 모델들과 비교했을 때, ESPCN이 높은 성능을 유지하면서도 가장 짧은 실행 시간을 나타내고 있습니다. 그리고 ImageNet으로 훈련한 9-5-5 SRCNN과 비교했을 때, rxr배만큼 컨볼루션의 수가 줄었고, 총 파라미터 수가 2.5배 줄어서, SR 동작에 필요한 시간이 2.5 x r x r배 줄었다고 합니다.
원 논문
: https://arxiv.org/pdf/1609.05158.pdf
참고 사이트
: https://hoya012.github.io/blog/SIngle-Image-Super-Resolution-Overview/
'딥러닝 & 머신러닝 > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] CNN - RepVGG (CVPR 2021) (0) | 2021.12.28 |
|---|---|
| [논문 리뷰] Super Resolution - MSRN (ECCV 2018) (0) | 2021.07.19 |
| [논문 리뷰] Super Resolution - VDSR (CVPR 2016) (0) | 2021.06.18 |
| [논문 리뷰] Super Resolution - SRCNN (ECCV 2014) (0) | 2021.06.17 |
| [논문 리뷰] GAN - CatGAN (ICLR 2016) (0) | 2020.04.28 |



