MSRN은 다음과 같이 한 문장으로 말할 수 있겠습니다. "MSRB라는 블록을 이용해 서로 다른 사이즈의 feature들을 효과적으로 사용하였으며, hierarchical feature fusion을 이용해 LR 이미지의 특징 하나하나를 최대한 사용하였다. 이를 통해 비슷한 시기에 나온 EDSR 보다 성능은 조금 떨어지지만 훨씬 가벼운 모델인 MSRN을 만들었다"
~ Multi-scale Residual Network for Image Super-Resolution ~
# 1. Introduction
single-image super-resolution(SISR)은 학계와 산업계에서 많은 관심을 끌고 있습니다. SISR은 LR 이미지로부터 HR 이미지를 reconstruct하는 ill-posed된 문제입니다. 왜냐하면, LR과 HR 사이를 연결하는 매핑(mapping)하는 함수의 정답은 여러 가지가 있을 수 있기 때문입니다. 그 때문에, 많은 양의 데이터셋을 이용해 LR 이미지로부터 HR 이미지를 매핑하려는 여러 가지 기법들이 존재합니다. 지금까지 딥러닝을 이용해 SR을 하려고 한 모델들로, SRCNN, EDSR, SRResNet 등이 있습니다. SRCNN은 딥러닝을 이용한 SR 모델의 선구자이며, EDSR과 SRResNet은 아주 좋은 성능을 보여준 모델들입니다.
그럼에도 불구하고, 그러한 모델들은 깊고 복잡하게 설계되는 경향이 있습니다. 그리고 그것은 결국 그 모델들이 더 많은 시간과 자원, 그리고 잡기술(trick)을 사용한다는 뜻입니다. 저자들은 실험을 하면서 기존 SR 모델에 다음과 같은 세 가지 문제점이 존재한다고 말합니다.
(a) 재현(reproduce)성의 어려움 : 똑같은 결과를 재현하기 힘듭니다. SR 모델들은 사소한 구조 변화에 민감하고, 원 논문의 모델 정보가 조금 없어서 그냥 구현하면 원 논문의 성능을 따라가기 힘들기 때문입니다. 그리고 같은 모델이어도 훈련 방법에 따라 성능이 다릅니다. 결국 성능 향상을 위해선 모델 구조 변화 뿐만 아니라 알려지지 않은 훈련 방법도 고려해야 됩니다. 한편 논문에선 그러한 훈련 방법을 새롭게 제시하는게 아니라, 그렇게 신기한 훈련 방법 없이도 쉽게 훈련할 수 있는 모델을 제안하겠다는 의미가 내포된 듯 합니다.
(b) 불충분한 특징(feature) 사용 : 많은 SR 방법들은 LR 이미지의 feature의 완전한 활용을 무시한 채, 오직 성능만을 올리기 위해 맹목적으로 모델 깊이를 늘립니다. 하지만 모델 깊이가 깊어질수록, 원래 이미지, 즉 LR 이미지의 feature들은 점점 사라지게 됩니다. feature를 완전히 활용하는 것은 HR 이미지 만드는 데 있어서 중요한 점입니다.
(c) 별로인 확장성 : LR 이미지를 전처리하여 모델에 넣는게 복잡성을 증가시키고 artifact를 만들기 때문에, 요즘 연구들은 LR 이미지를 전처리 하지 않고 그냥 바로 모델에 넣는 쪽으로 갑니다. 그 결과, 모든 upscaling factor를 사용하거나 혹은 모델 구조를 조금만 바꿔서 모든 upscaling factor를 사용하는, 그런 간단한 SR 모델은 찾기 힘듭니다. (이것은 아마 SRCNN같이 주로 전처리 과정에서 upscale이 이뤄지는 문제를 짚은 것 같습니다. ESPCN의 PixelShuffle 등장 이전까지는 LR 이미지 upscale을 모두 전처리 과정에서 미리 해놓고 그것을 모델에 넣었습니다.)
위와 같은 문제들을 해결하기 위해, MSRN(multi-scale residual network)을 제안합니다. 이 MSRN 모델은 MSRB(multi-scale residual block)라는 블록으로 주로 구성되어 있습니다. MSRN의 주요 특징 5가지는 다음과 같습니다. 각 항목들은 뒤에서 더 자세히 다룹니다.
1) 각기 다른 scale에 대한 이미지의 feature를 얻기 위해 MSRB를 사용합니다. 그리고 이 feature들은 local한 multi-scale feature입니다. (여기서 말하는 scale은 upscale factor의 scale이 아니라 컨볼루션 필터 사이즈의 크기를 뜻합니다)
2) 각 MSRB를 통과한 아웃풋들은 global feature fusion을 위해 합쳐집니다.
3) "local한 multi-scale feature들이 합쳐진 것"과 "융합된(fusion) global feature들"은 LR 이미지의 사용을 극대화하고, feature 전송 과정에서 feature disappear 문제를 해결합니다.
4) global feature fusion을 위해 1x1 conv를 사용합니다.
5) 간단하지만 효율적인 복원(reconstruction) 구조를 사용하며, 모든 upscaling factor를 쉽게 사용할 수 있습니다. 즉, 문제점 (c)를 해결합니다.
저자들은 다른 특별한 훈련 방법없이 모델을 훈련시켰는데, 그만큼 누구나 모델을 재현하기 쉽다는 것을 보여줍니다. 또한 MSRB의 갯수를 늘리거나 훈련용 이미지의 크기를 늘림으로써 성능이 높아지는 것을 확인했습니다. 그리고 MSRB는 다른 복원(restoration) 모델에 적용될 수 있다는 것도 밝혔습니다. 이를 비롯한 논문의 큰 기여점들은 다음과 같습니다.
- MSRB를 통해 LR 이미지의 feature들을 최대한 사용함으로써, 이미지 feature들을 잘 감지할 수 있을 뿐만 아니라(문제점 (b)에 언급됨), 각기 다른 scale에서 feature fusion을 할 수 있습니다.
- MSRB는 깊은 구조 없이도 SISR에서 최고 성능을 나타냈고, 다른 복원 task에서도 사용될 수 있습니다.
- 이미지 복원과 hierarchical feature fusion(계층적 특징 융합, HFFS)을 위한 간단한 구조를 제안했으며, 이것은 모든 upscaling factor에 대해서도 활용 가능합니다.
# 2. Related Works
- Single-image Super-resolution -
딥러닝이 등장하기 이전에는 linear나 bicubic 같은 interpolation 기법이 있었습니다. 그 방법들은 빠르지만 디테일하지 못합니다. 좀 더 기술이 발전하여, LR 이미지와 HR 이미지 사이의 매핑 함수를 설계하는 방법들이 나왔습니다. 그 방법들은 neighbor embedding부터 sparse coding까지 다양한 기술을 사용합니다.
최근 들어서는 LR에서 HR 이미지를 매핑하는 함수를 만들기 위해 큰 훈련용 데이터셋을 사용해서 end-to-end CNN 모델을 만듭니다. 그 시초는 SRCNN입니다. SRCNN을 비롯한 이전 연구들에선 LR 이미지를 정해진 upscale factor로 bicubic interpolation 방법을 이용해 HR 이미지와 같은 해상도를 갖도록 전처리를 합니다. 그러나 이 방법은 모델 연산량을 증가시키고, artifact를 만든다는 단점이 있습니다.
이러한 단점을 해소하기 위해, FSRCNN, ESPCN 등의 모델이 제시되었습니다. VDSR의 등장 이후, 모델의 깊이를 늘려서 성능 향상을 꾀한 SR 모델들이 많아졌습니다. DRCN, DRNN, LapSRN, SRResNet, EDSR 등이 그렇습니다. 그러나 모델이 깊어지면 깊어질수록 훈련은 점점 어려워집니다.
- Feature Extraction Block -

현재까지 많은 특징 추출(feature extraction) 블록이 제안되었습니다. 크게 Residual, Dense, Inception 블록이 있습니다. 그러나 저자들은 각 블록에 단점이 있다고 합니다. Inception 블록의 경우는 단순히 다른 크기들을 가진 컨볼루션 필터를 통과한 이미지의 feature를 합친다는 점에서, 국소적인(local) 영역의 feature를 쓰지 못한다고 합니다. Dense 블록은 Residual 블록과 마찬가지로 하나의 컨볼루션 필터 사이즈를 쓰지만, growth rate가 증가할수록 Dense 블록의 복잡도가 증가한다고 합니다.
이러한 문제점들을 해결하기 위해, 저자들은 multi-scale residual block, MSRB를 제안합니다. Residual 구조에 기반하여, 각기 다른 scale의 이미지 feature들을 적절히 찾아낼 수 있는, 각기 다른 크기의 컨볼루션 필터를 도입합니다. 여기에, 각기 다른 scale의 feature들 사이에 skip connection을 적용함으로써 feautre 정보들이 서로 공유되고 재사용될 수 있도록 합니다.
이것은 이미지의 local한 부분도 최대한 활용할 수 있도록 도와줍니다. (각기 다른 scale을 가진 필터로 특징을 뽑아낼뿐만 아니라, 그 특징들을 서로 공유하고 재사용하므로) 그리고 MSRB의 맨 끝에 있는 1x1 conv은 bottleneck처럼 쓰여, feature fusion과 복잡도 줄이기에 기여하게 됩니다.
# 3. Proposed Method
연구의 목표는 LR 이미지 I_LR과 HR 이미지 I_HR 사이의 end-to-end 매핑 함수 F를 찾는 것입니다. 다른 연구들과 마찬가지로, 이미지를 YCbCr로 바꾼 후 Y 채널에 대해서만 훈련합니다. 이미지가 C개의 컬러 채널을 가지고 있을 때, I_LR의 사이즈는 H x W x C로 표현됩니다. I_HR은 rH x rW x C로 표현되며, C=1일때 Y 채널만 사용한 것을 의미하며 r은 upscale factor를 나타냅니다. (이 문단의 내용이 대부분의 SR 모델에서 이미지 준비 과정을 잘 나타냅니다)
θ={W_1, W_2, ... ,W_m, b_1, b_2, ... ,b_m}은 신경망에 존재하는 가중치와 bias 집합을 나타냅니다. 신경망의 목적은 실제 그리고 이때 쓰이는 loss function L_SR은 아래 수식과 같이 L1 loss function입니다. 모델은 훈련을 통해 정답 이미지인 I_HR과 I_LR을 모델에 넣어서 만들어진 F(I_LR) 간의 차이를 나타내는 loss function의 값을 최소화하는 θ를 찾게 됩니다.
- Multi-scale Residual Block (MSRB) -
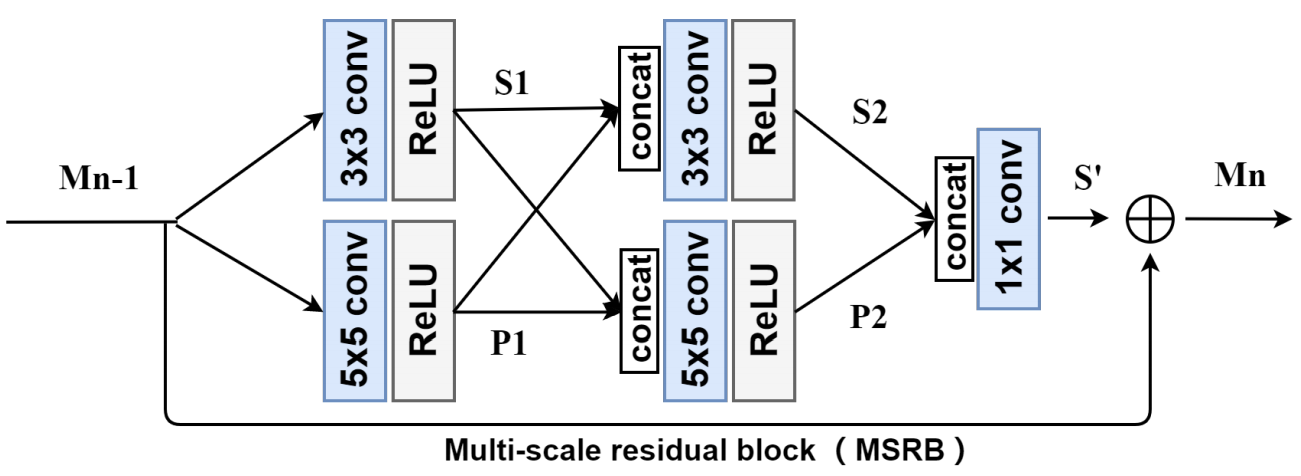
MSRB는 크게 multi-scale features fusion과 local residual learning 부분으로 구성되어 있습니다.
* Multi-scale Features Fusion *
각기 다른 스케일의 컨볼루션 필터를 가진, 두 개의 서로 다른 bypass network를 사용함으로써, bypass 사이의 정보가 각기 공유됩니다. 그럼으로써 각기 다른 스케일에서의 이미지 feature들을 찾을 수 있습니다. MSRB의 자세한 동작 과정은 아래 수식과 같습니다.

* Local Residual Learning *
아마 MSRB 안에서만 동작하기 때문에 "local"한 residual learning이라고 한 것 같습니다. 이것은 shortcut connection과 element-wise 덧셈으로 이루어지며, 계산 복잡도를 크게 줄여주고 모델 성능도 올려줍니다. MSRB의 인풋인 M_n-1이 S'과 더해져서 MSRB의 아웃풋 M_n이 되는 형태입니다. 수식은 아래와 같습니다.
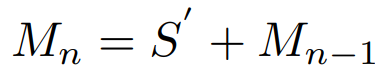
- Hierarchical Feature Fusion Structure (HFFS) -
SR에서, 인풋인 LR과 정답인 HR 이미지는 높게 연관이 되어있어서, 인풋 이미지의 feature를 최대한 뽑아내고, 이미지 복원을 위해 그것을 모델의 끝단에 손실없이 전달하는게 중요합니다. 그러나, 당연히 모델의 깊이가 깊으면 깊어질수록 feature가 전달되는 동안 점점 그 정보는 옅어집니다.
이러한 문제의 해결을 위해 많은 방법들이 제안되었고, 그 중 skip connection은 가장 간단하고 효율적인 방법으로 알려져있습니다. skip connection을 포함한 그러한 방법들은 서로 다른 레이어를 연결하는 또 다른 연결을 만든다는 점이 공통점입니다. 그러나, 그러한 방법들은 살펴보면 인풋 이미지의 feature들을 최대한 사용하지 못하며, 목적에 맞지 않는 잉여 정보들도 만든다는 단점이 있습니다.
실험을 해보니, 모델 깊이가 깊어질수록, 네트워크의 공간 표현 능력은 점점 감소하는 반면, 의미 표현 능력은 점점 증가하는 것을 알 수 있었다고 합니다. 이는 전체적인건 점점 잘 보는데 세부적인걸 점점 못 본다는 뜻 같습니다.
별개로 추가적으로, MSRB 각각의 아웃풋은 확실한 feature들을 가지고 있었다고 합니다. (이는 잠시 후의 figure를 보면 알 수 있습니다) 따라서, 그러한 hierarchical(계층적) feature들을 사용하는 방법은 복원된 이미지의 퀄리티에 즉각적으로 영향을 미칩니다. 이 연구에선, 간단한 hierarchical feature fusion 구조가 사용되었습니다.
이 연구에선 MSRB의 아웃풋 feature map들을 이미지 복원을 위해 모델의 끝으로 보냅니다. 한쪽으론, 그 feature map들이 많은 양의 잉여 정보를 포함하고 있었으며, 다른 한쪽으론, 그것들을 바로 사용하는 것이 계산 복잡도를 크게 증가시켰습니다. 그렇게 계층적인 feature들로부터 유용한 정보만 적절히 뽑기 위해서, 이 연구에선 1x1 conv를 가진 bottleneck 레이어를 사용하였습니다.
* hierarchical feature *
깊이가 깊어질수록 공간 표현 능력은 줄어들지만 의미 표현 능력은 증가하는, 그러한 feature의 특징을 hierarchical 하다고 하는 것 같습니다. 보통 모델 깊이가 깊어질수록 feature map 사이즈가 줄어듭니다. 이때 모델의 깊이가 얕을수록, 즉, feature map 사이즈가 원본에 가까울수록 원본을 잘 표현하는, "공간적 표현 능력(spatial expression ability)"이 증가하게 되며, 모델의 깊이가 깊을수록, 즉, feature map 사이즈가 점점 줄어들수록, 이미지의 압축된 정보를 가지게 되므로 "의미적 표현 능력(semantic expression ability)"이 증가하게 되는 것 같습니다. hierarchical feature 각각은 MSRN의 M_0, M_1, M_2, ... ,M_n들을 뜻합니다. 1x1 conv를 사용해 hierarchical feature를 사용하는 공식은 아래와 같으며, [ ] 부분은 concat 부분입니다.
- Image Reconstruction -
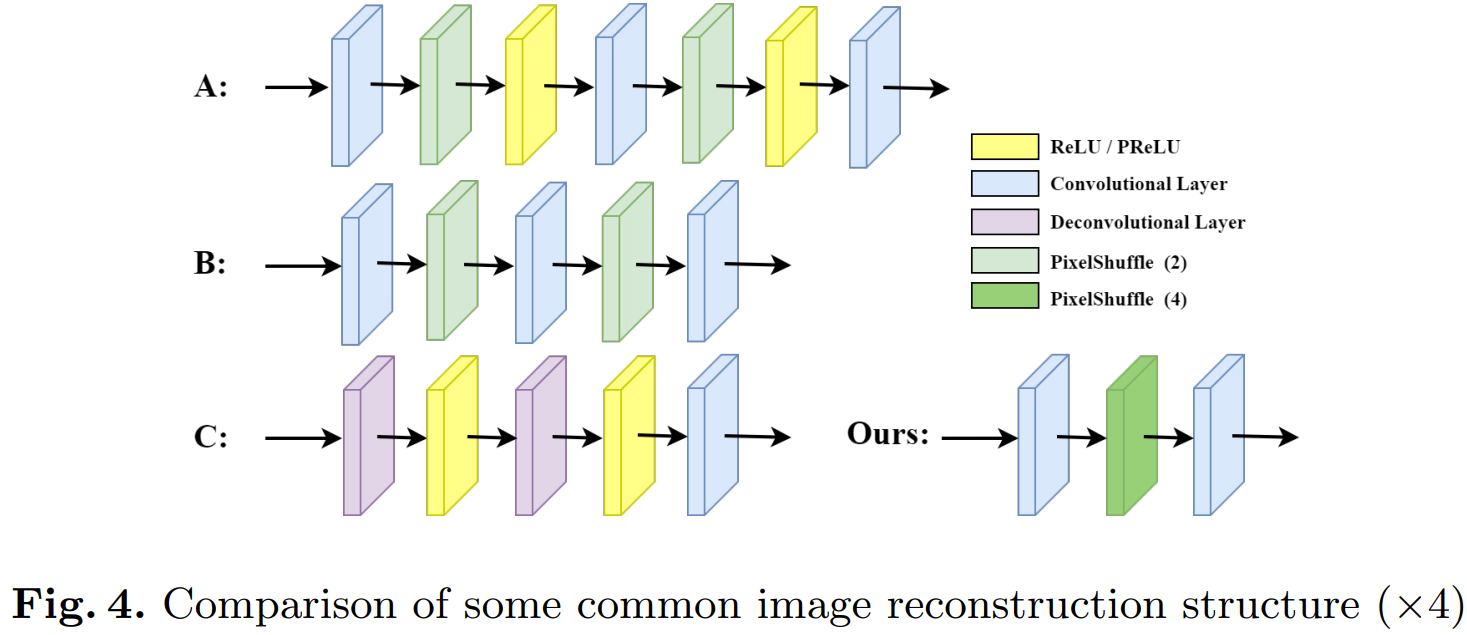
모델이 LR과 HR 이미지 간의 매핑 함수를 배우기 위해, 이전 연구들은 모델에 넣기 전의 LR을 HR과 같은 크기(해상도)가 되도록 bicubic으로 upsample 하였습니다. 그러나 이 방법은 잉여 정보와 계산 복잡도를 증가시켰습니다.
이런 문제점에 의거해서, 최근 연구들은 (ESPCN같이) 그냥 LR을 모델에 넣으면 모델 통과 시에 HR과 같은 크기가 되도록 만들었습니다. 그러나 그러한 모델들 중 네트워크의 구조 조금만 바꿔도 모든 upscaling factor를 사용할 수 있도록 만든 것은 찾기 어렵습니다. 게다가, 많은 네트워크들은 하나의 고정된 upscaling factor에 대해서만 만들어진 경향이 있습니다.
LR 이미지를 HR 이미지로 모델 안에서 upsample 하기 위해, pixelshuffle과 deconv가 많이 쓰입니다. 위 그림은 모두 x4로 upscale 할 때를 예로 든 것입니다. x2에 대한 pixelshuffle을 두번 쓰면 x4가 되는 형식입니다. 그런데 A, B, C 방법은 x8 등으로 크게 upscale할 땐 훈련에 불확실한 문제가 있을수도 있고, x2, x4, x8, ... 같이 지수적으로 upscale하는게 아닌, x3, x5, ... 처럼 점진적으로 증가시키고 싶을 때도 있습니다. 이때 홀수 upscale factor로는 사용을 못한다는 문제점이 있습니다.

이 연구에선 pixelshuffle의 숫자 하나(여기서는 M)만 간단하게 바꿔서 해결하였습니다. (위 표 참고) 확실한 건 아니지만, 아마 파이토치에선 여기서 제안한 방법이 구현된 듯합니다. (nn.PixelShuffle(3) 등등) 이미 이걸 알고 있던 저에겐 너무 당연한 말이어서 왜 이런걸 제안했지? 싶었습니다.. 실제로도 공식 코드 상에서 뭐 특별한 걸 쓴 게 아니라 그냥 nn.PixelShuffle()을 사용합니다.
# 4. Experiments
- Datasets -
DIV2K를 훈련용 데이터 셋으로 사용하였으며, 테스트 시에는 가장 널리 쓰이는 데이터 셋인 Set5, Set14, BSDS100, Urban100, Manga109를 사용했습니다. 훈련과 테스트 모두 YCbCr에서 진행되었으며, upscale factor는 x2, x3, x4, x8이 훈련과 테스트 시에 사용되었습니다. PSNR과 SSIM 모두 Y채널(휘도)에서만 측정되었습니다.
- Comparisons with State-of-the-art Methods -
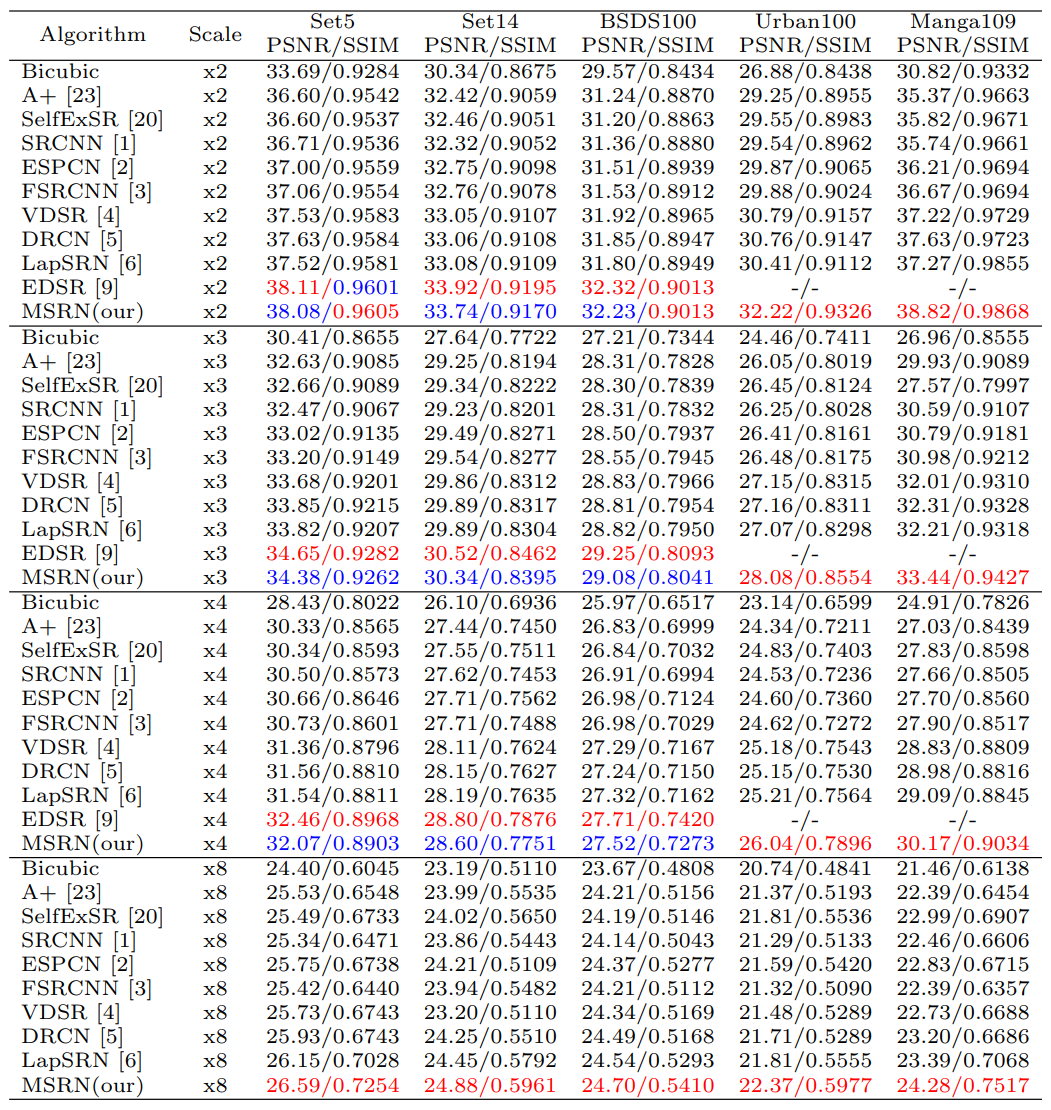
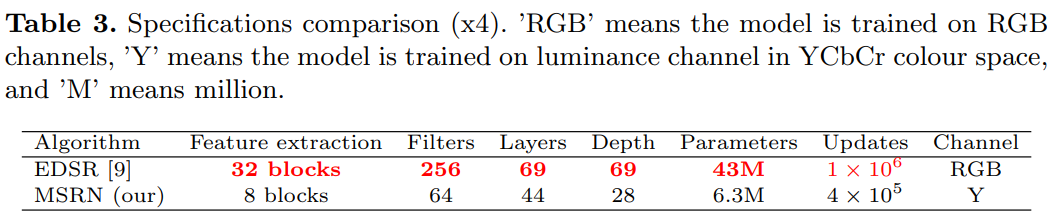

위의 첫번째 표는 MSRN과 기존 SOTA 모델들과의 PSNR/SSIM을 비교한 것입니다. 보시면 x2 upscale factor를 제외한 나머지 scale factor에서는 모두 EDSR이 MSRN 보다 근소하게 좋은 것을 확인할 수 있습니다. 그러나 두번째 표를 보시면, x4의 upscale facotr에서 EDSR과 비교했을 때 MSRN의 복잡도가 훨씬 적고, MSRN은 훈련도 Y채널에 대해서만 합니다. 이는 곧 훈련이 좀 더 쉽고, 모델 재현 또한 더 쉽다는 것을 의미합니다. 위 그림은 MSRN과 SRCNN, LapSRN과의 차이를 보여줍니다.
- Benefit of MSRB & Benefit of Increasing The Number of MSRB -
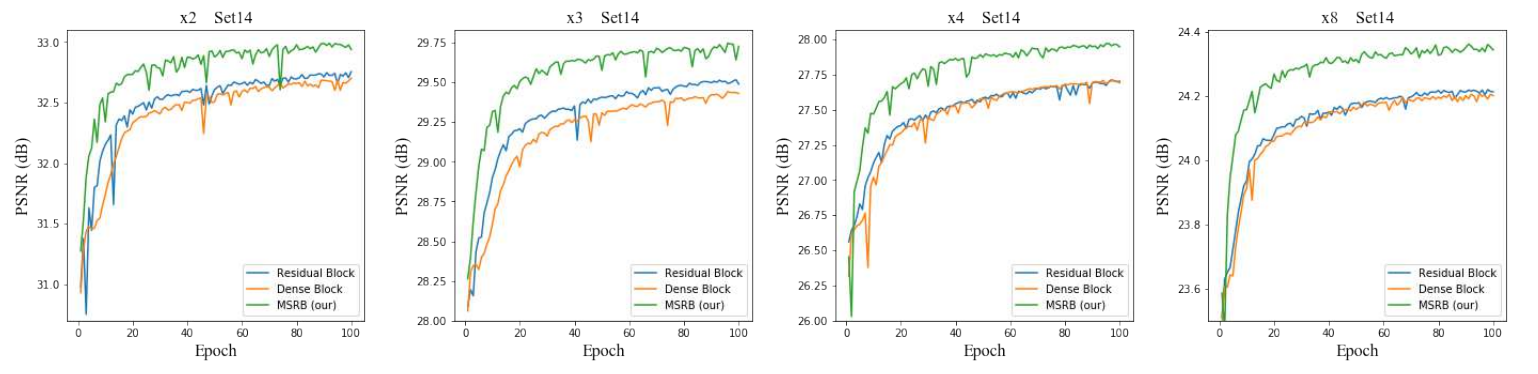
또한 각기 다른 upscale factor에서 Residual, Dense 블록과 비교해봤을때, MSRB 블록이 훨씬 성능이 좋은 것으로 밝혀졌습니다.
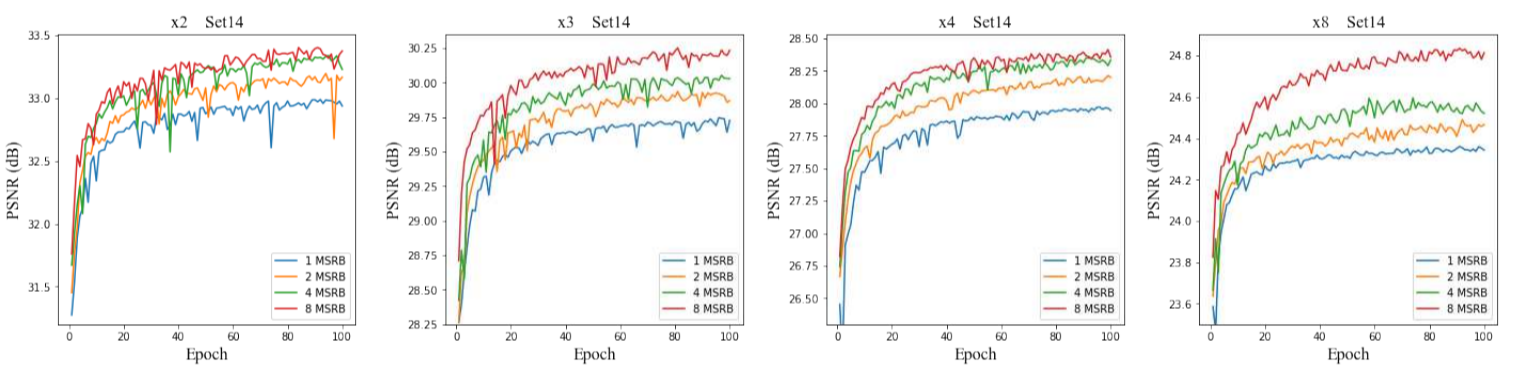
그리고 각기 다른 upscale factor에서 MSRB의 갯수가 많아질수록, 즉 모델의 깊이가 깊어질수록 성능이 증가하는데, 이는 MSRB를 이용해 더욱 "효율적으로" 모델의 깊이를 깊게 했기 때문에 효과적으로 LR 이미지의 feature를 활용한 결과라고 볼 수 있을 것 같습니다. 한편 단순히 MSRB를 추가할수록 성능이 좋아지긴했지만 모델 복잡도가 증가했습니다. 그럼에도 불구하고, 모델 복잡도와 성능을 저울질한 결과, 8개의 MSRB를 썼을 때 EDSR과 성능이 비슷해졌지만 파라미터는 7배나 줄어들었습니다.
- Performance on Other Tasks -
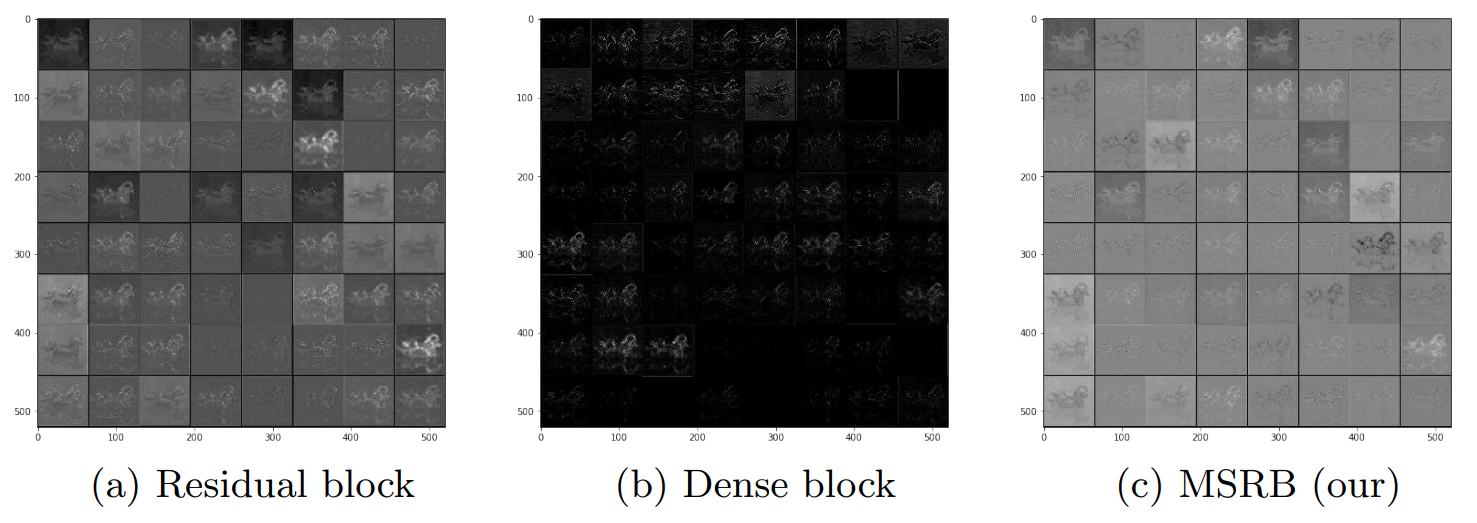
위 그림을 보면, feature map이 layer를 통과했을 때 activation 되는 영역, 즉 특징이 잘 드러나는 영역이 MSRB가 다른 블록보다 더 많은 것을 확인할 수 있습니다. 검은색으로 나타나면 activation이 0으로, 즉 신호가 죽은 것입니다. 위에서 언급한 "MSRB 각각의 아웃풋은 확실한 feature들을 가지고 있었다"라는 문장의 의미가 이 그림에서 드러납니다.

또한 위 그림에서 볼 수 있듯이, MSRB는 denoising이나 dehazing같은 low-level vision task등에서도 유용하게 사용될 수 있다고 합니다.
원 논문
: https://arxiv.org/pdf/1904.10698.pdf
오피셜 코드
'딥러닝 & 머신러닝 > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Super Resolution - RFDN (ECCVW 2020) (0) | 2022.01.02 |
|---|---|
| [논문 리뷰] CNN - RepVGG (CVPR 2021) (0) | 2021.12.28 |
| [논문 리뷰] Super Resolution - ESPCN (CVPR 2016) (0) | 2021.06.18 |
| [논문 리뷰] Super Resolution - VDSR (CVPR 2016) (0) | 2021.06.18 |
| [논문 리뷰] Super Resolution - SRCNN (ECCV 2014) (0) | 2021.06.17 |



