RepVGG는 올해 나온 논문 중 제가 가장 처음으로 읽어본 논문입니다. 7월 중순 쯤에 무슨 논문을 읽어볼까 고민하던 중, 미국 트럼프 대통령의 "Make America Great Again"이라는 선전 문구를 패러디한 제목이 인상깊어 읽게 되었습니다. 제목으로 인한 어그로(?) 덕분에 읽기 시작했지만, 지금은 이 논문에서 중요하게 다루는 re-parameterization에 대해 깊이 매료되었습니다. 앞으로는 해당 기법을 활용해 연구도 하고 싶습니다.
RepVGG는 다음과 같이 한 문장으로 말할 수 있겠습니다. "훈련(train) 때는 3x3, 1x1, Identity convolution으로 이루어진 multi-branch 모델을 사용하되, 추론(inference) 때는 re-parameterization이라는 기법을 사용해 multi-branch를 3x3 convolution으로만 이루어진 plain 모델로 바꿔 활용할 수 있다. 이를 통해 multi-branch로 더 정교하게 훈련된 가중치와 더 빠른 추론 속도를 얻을 수 있다. 그리고 3x3 conv에 최적화된 추론용 하드웨어에 아주 적합한 모델이다."
~ RepVGG: Making VGG-style ConvNets Great Again ~
# 1. Introduction
CNN(Convolutional Neural Network)은 지금까지 많은 발전을 이뤄왔습니다. 클래식하게 conv를 쌓아올린 VGG, multi-branch를 처음 도입한 Inception, residual block을 도입한 ResNet, dense connection을 도입한 DenseNet, 그리고 최근에는 NAS와 compound scaling을 활용한 모델까지 등장했습니다. 이처럼 모델이 점점 발전하면서 복잡해졌고, 보통은 모델이 복잡해질수록 성능은 점점 올라가는 경향을 보였습니다. 그러나 그에 따른 단점 또한 명확합니다. 첫째, Inception의 branch-concatenation 같이 복잡한 multi-branch 구조를 사용해 모델을 만들거나 활용하기 어렵습니다. 둘째, Xception이나 MobileNet 등에 있는 depthwise conv는 메모리 할당 비용이 늘어난다거나, 몇몇 하드웨어 장치에서 지원되지 않는다는 단점이 있습니다. 셋째, 그렇기 때문에 최신 모델보다 VGG나 ResNet 같은 예전 모델이 속도가 더 빠를 때가 많아서 (즉 FLOPs가 작아서), 여전히 그러한 모델들은 산업과 학계 등에서 다방면으로 활용됩니다.
저자들은 최신 모델들의 단점인 복잡성, 느린 스피드, 하드웨어 장치 범용성 등을 해결함과 동시에, 높은 성능을 달성한 모델인 RepVGG를 소개합니다. (추론 시에 사용하는) RepVGG는 VGG 형태의 plain 모델, 즉 3x3 conv와 ReLU를 정직하게 그대로 쌓은 형태며, 그 형태는 automatic search, manual refinement, compound scaling 등의 방법을 전혀 쓰지 않고 만든 것입니다.
그런데 그렇게 간단한 형태만 가지고서 어떻게 최신 모델보다 더 좋은 성능을 달성했는가 의문이 들 수 있습니다. 저자들은 multi-branch를 도입하고자 했습니다. ResNet같은 multi-branch 모양의 모델은 얕은 모델 여러 개의 내재된 앙상블과도 같아서 (똑같은 input을 한번 더 더하므로), 그러한 모델을 훈련하는 것은 gradient vanishing 문제 피하는데도 좋기 때문입니다. 그런데 아까 위에서는 plain VGG 구조를 따라했다고 하지 않았느냐?라고 할 수 있는데, 핵심은 그 구조는 '추론'할 때만 사용한다는 점입니다.

RepVGG는 훈련(train) 때와 추론(inference) 때 사용하는 모델의 형태(topology)가 다릅니다. 훈련 때는 multi-branch 모델을 사용하고, 추론 때는 plain 모델을 사용합니다. 그리고 전자 모델에서 후자 모델로 바꾸는 방법이 바로 structual re-parameterization입니다. 이 기법은 원래 네트워크 구조를 그것의 가중치 변환을 통해 원래 것에서 다른 것으로 바꾸는 방법입니다. 즉, 특정 구조의 가중치가 다른 구조와 결합된 다른 가중치 세트로 변환될 수 있다면 전자를 후자로 동등하게 대체할 수 있으므로 전체 네트워크 구조가 변경됩니다. 설명이 다소 추상적일 수 있는데, 잠시 후 더 자세히 설명드리겠습니다.
그림1을 보면 더 잘 이해할 수 있습니다. (B)에서, 훈련 때 사용했던 원래의 3x3 커널, 1x1 커널, identity 커널, 그리고 BN의 가중치들로, (C)에서, 추론 때 사용할 3x3 커널만 있는 모델을 만들 수 있습니다. 즉, multi-branch를 가지고 훈련된 가중치를, 추론 때 3x3 conv와 ReLU만 가진 plain 구조에서 사용하므로, "multi-branch로 더 정교하게 훈련된 가중치 + 더 빠른 추론 속도"의 두마리 토끼를 동시에 잡을 수 있게 됩니다.
# 2. Related Works
ResNet, Inception, DenseNet, 그리고 NAS(neural architecture search)를 순서대로 설명합니다. branch가 없는 모델에서 branch가 있는 모델로 넘어오며 어떤 특징이 있었고, 그로 인해 성능 향상이 얼마나 있었으며, 그에 따른 복잡성과 낮은 활용성 등에 대한 단점들도 언급합니다.
2-2. Effective Training of Single-path Models
지금까지 plain하고 simple한 모델들을 효과적으로 훈련해서 SOTA 모델보다 더 성능을 올리려는 시도는 있었지만, 대부분 실패했다고 합니다. 그러면서 동시에, 자신들의 RepVGG는 합리적인 모델 깊이, 괜찮은 성능과 스피드 간의 trade-off 관계, 간단한 수식으로 쉽게 구현할 수 있는 모델 구조 등의 장점을 내세우며, 간단한 모델로도 SOTA 성능을 찍을 수 있다고 말합니다.
2-3. Model Re-parameterization
저자들은 이전부터 Re-parameterization에 대해 연구했었습니다. DiracNet은 skip connection을 추가하는 대신 Dirac-delta function과 함께 Dirac re-parameterization을 사용하여 plain한 딥러닝 모델을 구축하고 훈련하는 형태입니다. Asymmetric Conv Block, DO-Conv, ExpandNet은 RepVGG와 비슷하게 블록(=conv들의 묶음)을 하나의 conv로 바꾸는 구조를 갖고 있습니다.
2-4. Winograd Convolution
표1은 똑같은 배치 사이즈와 인풋/아웃풋 채널 갯수를 가졌을 때 각 커널 사이즈에 따른 속도 비교를 한 표입니다. Theoretical FLOPs는 memory access delay, address generation delays 같은 사소한 overhead가 없다고 가정할 때의 FLOPs, Time usage는 실제 러닝 타임, TFLOPs는 Tera FLoating-point Operations Per Second의 약자이며, computational density를 측정할 때 TFLOPs를 썼다고 합니다. (그럼 처음부터 표에 computational density를 적고 단위를 TFLOPs로 적지 왜 굳이 저렇게..?) computational density는 이름에서도 알 수 있듯이, 그 크기가 클수록 계산 효율성이 좋다는 것을 나타냅니다. 보시면 3x3 conv일 때 NVIDIA 1080Ti GPU에서 가장 효율적이라는 것을 확인할 수 있습니다.
한편 winograd conv는 3x3 conv 연산을 가속화하는 알고리즘인데, 일반 3x3 conv보다 곱셈 연산의 양이 4/9로 줄어듭니다. 핵심은 곱하기 연산의 수를 줄이고 더하기 연산의 수를 늘리는 것입니다. 이때 RepVGG는 추론 때 3x3 conv로만 이루어진 모델을 사용합니다. 따라서 일반 3x3 conv에 winograd의 support가 들어간다면 추론 속도는 더욱 빨라질 것입니다. 실제로 후에 소개할 성능 분석 표에서는 winograd의 support가 들어간 채로 모델 간의 속도 비교를 했습니다.
Fast : 최근에 나오는 multi-branch 모델들은 VGG보다 이론적 FLOPs가 작지만, 속도는 VGG보다 느립니다. 예를 들어 VGG-16은 EfficientNet-B3보다 8.4배 많은 FLOPs를 가지고 있지만, 1080Ti에서 VGG-16이 1.8배 더 빠릅니다. 이러한 FLOPs와 속도간의 불일치는 두가지의 중요한 요인에 의해서 발생합니다. 그 요인은 바로 MAC(Memory Access Cost, 메모리 접근 비용)와 degree of parallelism(병렬도)입니다. 그것들은 속도에 큰 영향을 끼치지만 FLOPs에서는 고려하지 않습니다. MAC와 degree of parallelism은 ShuffleNet-V2 논문에서 소개된 개념입니다.
예를 들어, branch들끼리의 addition이나 concatenation에서 필요한 계산량이 무시할만한 상태더라도, MAC은 속도 측정에 있어서 중요한 요소입니다. 게다가 MAC은 groupwise convolution에서 많은 시간 사용량을 차지하기도 합니다. 또한 같은 FLOPs에서 degree of parallelism이 높을수록 속도가 더 빠를 수 있다고 합니다. ShuffleNet-V2에서는 하나의 큰 덩어리 연산을 작은 연산으로 쪼개는 것(network fragmentation)으로 degree of parallelism을 낮출 수 있다고 합니다. 예를 들어, 5x5 conv 1개를 3x3 conv 2개로 쪼갤 수 있는데, 이렇게 되면 degree of parallelism이 낮아진 것입니다.
그런데 이렇게 큰 커널을 가진 conv를 여러 개로 쪼개는 것은 정확도를 올리는 측면에선 나을 수 있습니다. 그러나 GPU 같이 대용량 병렬 처리를 위한 시스템에선 kernel launching이나 동기화(synchronization) 과정 등에서 overhead가 많이 발생해서 비효율적이라고 합니다. 'conv가 여러 개로 쪼개졌다'는 것을 여기서는 한 buliding block 안에 몇 개의 독립 conv와 pooling이 있는지 세어서 결정했는데, NASNET-A의 경우 13이고, ResNet의 경우는 2 또는 3이라고 합니다. 이 논문에서는 그 수를 오직 1, 즉 독립적인 conv만 사용해 degree of parallelism을 낮추지 않음으로써 연산 속도를 늘리려고 했습니다.
Memory-economical : multi-branch를 가진 모델들은 그것들을 더하거나 concat하기 위해서 multi-branch를 통과한 feature들을 유지하고 있어야 하는데, 이때 메모리가 낭비됩니다. 그림2에서도 하나의 feature를 나중에 더하기 위해서 가지고 있어야 하므로 중간에 계속 두배의 메모리를 차지하게 됩니다. (그런데 이 부분은 교수님과 제 생각에 틀린 거라고 생각했습니다. 왜냐하면 어차피 multi-branch로 훈련된 가중치를 추론 때도 계속 갖고 있는 것이니까, 추론 때 저렇게 plain 하게 모델 구조를 바꾼다 해도 memory 효율성이 증가할까... 하는 의문이 들었습니다.)
Flexible : multi-branch 형태의 모델은 구조적으로 여러 가지 제약이 있습니다. 이로 인해 쉽게 응용하기 어렵다는 단점이 있습니다. 첫번째 예로, ResNet에 있는 residual block의 마지막 conv는 인풋으로 들어온 텐서와 똑같은 모양의 텐서를 출력해야한다는 제약이 있습니다. 두번째 예로, channel pruning을 할 때도 residual connection 등이 있으면 pruning을 적용하기 어렵게 됩니다.
3-2. Training-time Multi-branch Architecture
plain한 모델은 지금까지 설명했듯이 많은 장점이 있지만, 좋지 않은 성능을 가지고 있다는 단점이 있습니다. 그리고 multi-branch 모델도 마찬가지로 지금까지 설명했듯이 추론 시에는 단점이 많지만, 훈련 시에는 장점이 있습니다. 예를 들어 gradient vanishing 문제를 해결해서 성능을 올릴 수 있다는 장점 등입니다. 따라서 저자들은 훈련 때만 multi-branch 모델을 사용하기로 합니다.
3-3. Re-param for Plain Inference-time Model
이 챕터에서는 훈련 때의 multi-branch 모델을 어떻게 추론 시에 plain 모델로 만드는 지에 대해 수식을 통해 구체적으로 설명합니다. 논문에서는 여러 가지 notation이 많아서 한번에 알아보기가 어려워, 제 방식대로 좀 더 간략하고 이해하기 쉽게 재작성했으니 참고하시길 바랍니다. 핵심은 1x1 conv와 identity conv를 모두 3x3 conv로 바꾸는 것, 그리고 conv + BN을 conv + bias로 바꾸는 것에 있습니다.
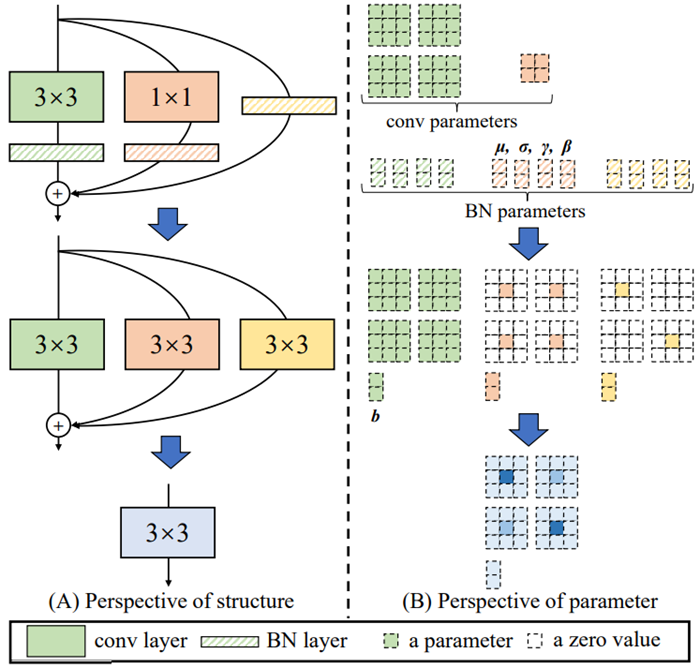
그림3을 기준으로 설명하겠습니다. 각 커널의 채널 수는 인풋 C1=2채널, 아웃풋 C2=2채널로 가정했습니다. 이때 가중치 갯수는 '입력 채널 수 x 출력 채널 수 x 커널 사이즈'이므로, 3x3 conv의 가중치 갯수는 C1xC2x3x3이고 1x1 conv의 가중치 갯수는 C1xC2x1x1이므로 C1=C2=2일때 저렇게 그려집니다. 즉, 3x3 크기의 커널이 총 2x2=4개가 있고, 1x1 크기의 커널도 2x2=4개가 있습니다. 1x1 conv의 각 주황색 사각형을 따로 떼주면 이해가 더 쉬울듯 했습니다. 그리고 bn을 이루는 하이퍼 파리미터들은 각각 아웃풋 채널 개수 C2=2만큼 계산이 됩니다.
초록색의 3x3 conv는 kernel size=3, stride=1, padding=1인 일반적인 3x3 conv 입니다. 그 다음엔 초록색 빗금으로 3x3 conv에 해당하는 BN이 있습니다. 초록색 3x3 conv에는 모든 색깔이 칠해져 있어서, 가중치가 각 커널에 꽉 채워져 있는 것을 알 수 있습니다.
주황색의 1x1 conv는 kernel size=1, stride=1, padding=1인 1x1 conv 입니다. 이때 보통 1x1 conv는 padding이 0인데, 1로 바뀌었다는 점이 특이합니다. 그리고 이 1x1 conv는 zero padding이 들어간 3x3 conv로 대체할 수 있습니다. 그것을 표현한 것이 바로 그림3.(B)의 주황색 1x1 conv의 가중치 주변에 점선으로 padding이 들어가 3x3 conv 모양이 된 것입니다.
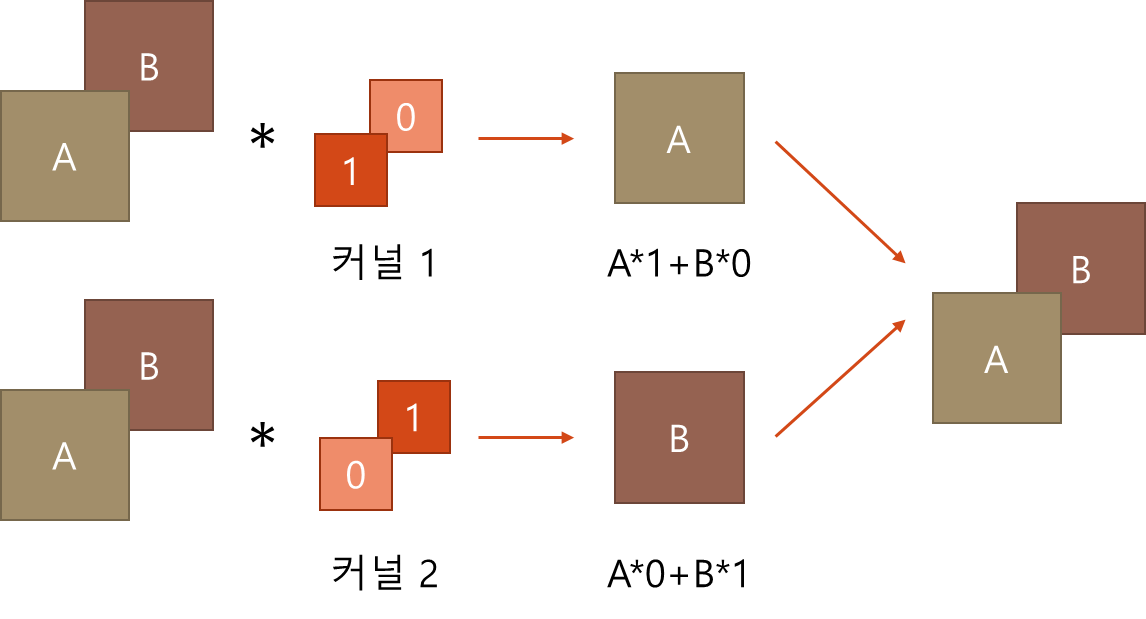
multi-branch의 가장 바깥쪽인 identity 부분은 아무것도 없는 것을 볼 수 있습니다. 즉 이 부분은 마치 residual connection 처럼 인풋 값을 그대로 더하되, BN 통과가 추가된 과정입니다. identity는 I = [[1 0][0 1]]^T 같은 identity matrix(단위 행렬)을 커널로 갖는 1x1 conv로 대체할 수 있습니다. 이 부분을 조금 이해하기 어려웠는데, 그림4를 보면 더 쉽게 이해할 수 있습니다.
identity layer는 그것을 통과한 C1개의 원본 feature map이 C2개의 커널을 거쳐 C2개의 원본 feature map을 그대로 만들어야 합니다. 그럼 그림4처럼 A,B feature map이 C1=2개가 있을 때, C2=2개의 커널 1,2도 각각 feature map의 갯수 C1=2개 만큼 있는 것입니다. (커널 자체에도 채널이 있고 그 채널 수는 인풋 feature map 갯수와 똑같습니다) 이때 1x1 conv의 커널로 생각하는 것이므로 각 크기는 1이고, 그 안의 가중치는 각각 그림4의 모양처럼 [1,0], [0,1]이어야 원본 feature map이 그대로 보존됩니다.
이때 C1과 C2가 같아야 원본 feature map이 그 개수도 그대로 보존되지 않을까 생각했는데, 예를 들어 C1=3, C2=32라고 생각해보면 [1,0,0,...,0], [0,1,0,...,0], [0,0,1,...,0], [0,0,0,...,0], ... ,[0,0,0,...,0] 이런 식으로 원본 feature map을 보존할 수 있는 행렬 3개만 identity matrix로 만들고, 나머지 행렬들은 모두 0으로 만들면 될 것 같습니다.
이제 identity layer도 1x1 conv로 변화시켰으니, 이 1x1 conv에 zero padding을 함으로써 3x3 conv를 만들 수 있습니다. 그 그림이 그림3.(B)의 노란색으로 표시되어 있습니다.
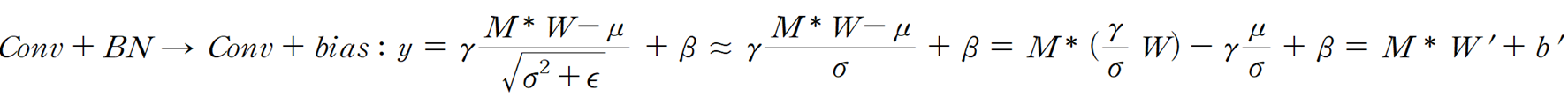
이제 conv + BN 조합을 어떻게 conv + bias 조합으로 바꿀 수 있는지 설명드리겠습니다. 논문에선 i번째 채널에 대해 수행한다는 것을 구체적으로 보여주기 위해 notation이 많아 복잡해 보이는데, 저는 그것들을 생략하고 간단하게 다시 나타내보았습니다. conv + BN에서 conv + bias으로의 변화는 그림3에선 BN의 4개 하이퍼 파라미터 μ, γ, β, σ가 bias b로 다시 표현된 것으로 나타납니다. W는 커널의 가중치 행렬, M은 feature map입니다.
BN 수식을 찾아보시면 처음엔 수식1의 y처럼 나타낼 수 있습니다. 이때 ε은 매우 작은 숫자이므로 생략 가능하다고 하면 루트가 벗겨지고, γ/σ가 W에 곱해졌다고 하면 새로운 W'를 만들 수 있고, 나머지 하이퍼 파라미터 μ, γ, β, σ의 조합으로 bias b'를 만들 수 있습니다. 그러면 이제 M, W를 가진 conv와 μ, γ, β, σ를 가진 BN이 M, W'를 가진 new conv와 b'를 가진 new bias로 변합니다.
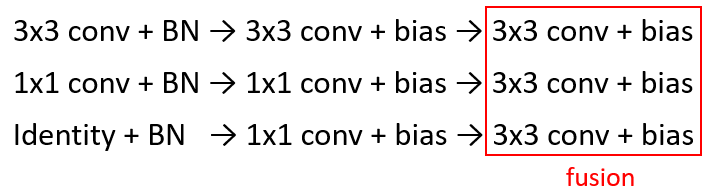
지금까지 3x3 conv + BN, 1x1 conv + BN, identity layer + BN를 모두 3x3 conv + BN으로 바꾸고, 그렇게 변한 3x3 conv + BN을 3x3 conv + bias로 바꾸었습니다. 이 과정을 모두 거쳤으니 3x3 conv + bias를 모두 fusion(융합)할 수 있습니다. 그 과정을 그림5처럼 간략하게 나타냈습니다. fusion을 거치면 그림3.(B)에선 파란색 가중치 행렬처럼 모든 가중치가 합쳐진 형태가 됩니다. 훈련된 모델에는 각 가중치가 커널에 저장되어 있을 것이고, 각 conv는 relu를 거치지 않으므로 서로 선형적으로 단순히 가중치를 더할 수 있습니다. 그렇게 함으로써, 하나의 큰 가중치 집합을 가진 통합 커널(파란색 가중치 행렬)을 만들 수 있게 됩니다.
3-4. Architectural Specification

이 챕터는 표2를 중심으로 RepVGG의 여러 버전에 대한 구체적인 구조를 설명합니다. RepVGG는 총 5개의 stage로 이루어져 있는데, 모두 3x3 conv로 이루어져 있습니다. 이때 pooling을 위해서 각 stage의 첫 레이어는 stride=2인 3x3 conv로 이루어져 있습니다. Max Pooling 레이어 등을 따로 쓰지 않는 이유는 모델의 feature 추출하는 모든 부분을 3x3 conv로 구성해서 fusion 할 수 있게 만들기 위함입니다. 그리고 이미지 분류를 위해서 global average pooling을 fully connected layer 뒤에 붙입니다.
모델 종류에는 크게 RepVGG-A와 RepVGG-B가 있는데, A는 각 스테이지마다 레이어가 각각 1, 2, 4, 14, 1개씩 있으며, B는 각 스테이지마다 레이어가 각각 1, 4, 6, 16, 1개씩 있습니다. A는 ResNet-18/34/50을 포함한 lightweight & middleweight 모델과 경쟁하고, B는 RegNet, ResNeXt 같은 heavy 모델과 경쟁하기 위해 설계되었습니다.
각 레이어의 채널은 [64a, 128a, 256a, 512b]로 구성됩니다. 이때 곱해지는 수(multiplier) 'a'를 사용하여 처음 4개 stage의 채널 개수를 조정하고 'b'를 마지막 stage의 채널 개수 조정에 사용합니다. b는 a보다 큰데, 마지막 stage의 레이어 개수는 1개이므로 채널을 늘려도 전체 모델의 파라미터 개수에는 큰 영향을 미치지 않기 때문입니다. 또한 가중치 수와 계산량을 줄이기 위해서, 선택적으로 홀수번째 레이어에 한해서 일반 3x3 conv 대신 groupwise 3x3 conv를 넣어서 실험했고, 이 경우 group의 수는 1, 2, 4였습니다.
# 4. Experiments

이 챕터에서는 실험 과정과 그 결과에 대해서 설명합니다. 자세한 실험 설계는 그림6을 참고하시면 될 것 같습니다. 그리고 성능 테스트는 모델의 모든 conv + BN을 3x3 conv + bias로 바꾼, 추론 모드에서 진행되었습니다.
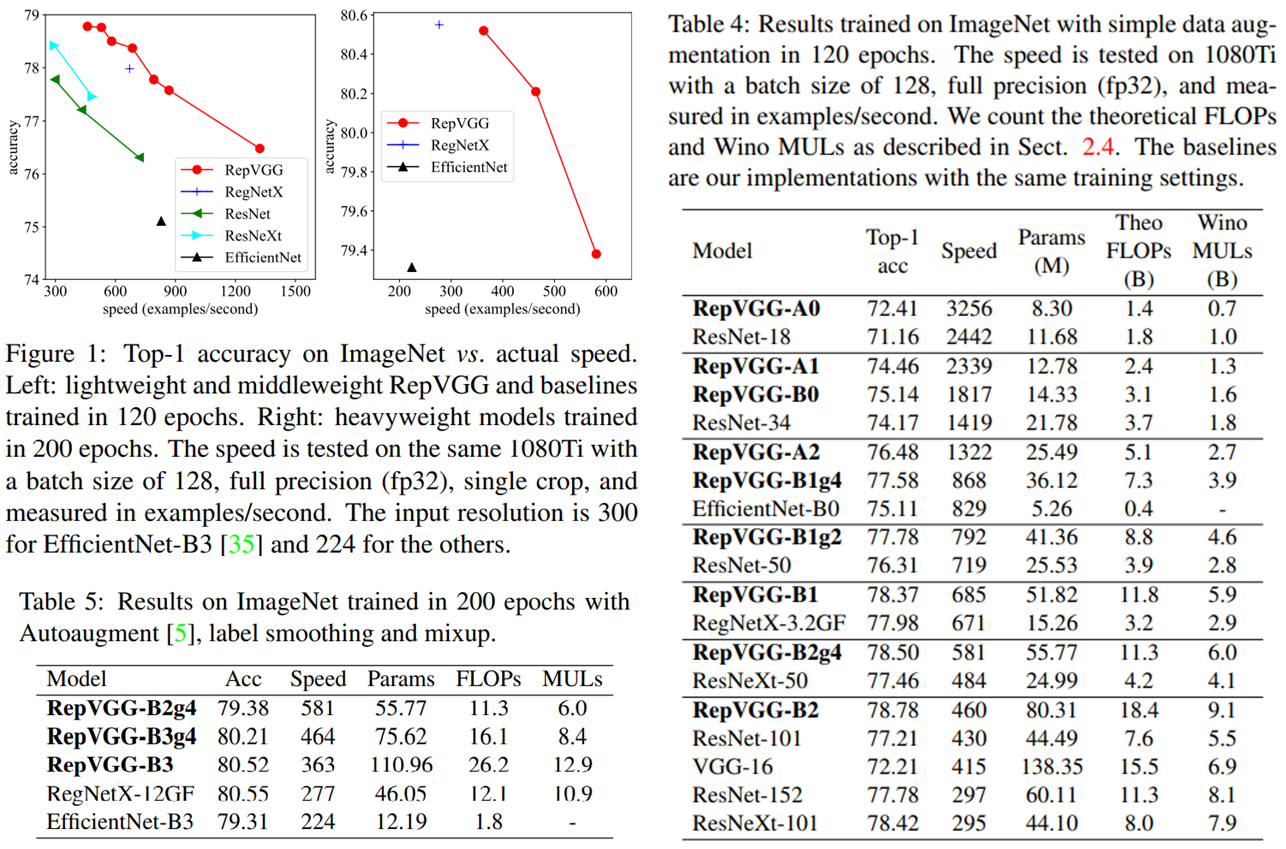
표3의 Figure1을 보면 Top-1 Accuracy가 같을 때 RepVGG가 다른 모델들보다 속도는 모두 더 빠른 것을 확인할 수 있습니다. 표3의 Table4를 보면, 특히 비슷한 성능이거나 더 나은 성능일 때, RepVGG는 ResNet 계열들보다 속도와 파라미터 수 두 관점에서 모두 우수합니다. 특히 RepVGG-B1g2와 ResNet-152는 같은 정확도를 달성했는데, RepVGG-B1g2가 속도는 약 2.66배 더 빠르고, 파라미터 수도 약 1.5배 더 적은 것을 확인할 수 있습니다. 다만 VGG 구조를 따른다는 점 때문에 RegNet, ResNeXt, EfficientNet 같은 최신 모델들에 비해선 파라미터 수가 꽤 많다는 단점 또한 확인할 수 있습니다.
이 논문에선 다른 모델과 달리 성능 비교 시에 2-4에서 언급한 Theoretical FLOPs와 Winograd MULs도 측정했습니다. Winograd conv는 위에서도 말했듯이 3x3 conv의 곱셈 연산을 많이 줄여줄 수 있으므로, 3x3 conv가 많은 RepVGG 같은 모델에서 유용하기 때문입니다. FLOPS와 Wino MULs가 높을수록 모델 속도는 느려집니다. VGG16과 ResNet-152를 비교해보면, VGG16이 ResNet-152보다 30%정도 빠릅니다. 그런데 FLOPs만 놓고 보면 VGG16이 더 높아 VGG16이 더 느려야하지만, Wino MULs를 보면 ResNet-152가 더 높습니다. 따라서 Wino MULs도 모델 속도에 중요한 영향을 끼치는데, RepVGG는 Winograd conv가 최적으로 사용될 수 있는 3x3 conv만 쓰므로 빠른 속도를 가질 수 있습니다.

표4의 Table6를 보시면, identity branch와 1x1 branch가 모두 있는 경우 성능은 제일 좋지만 추론 시 속도는 가장 느리고, 모두 없는 경우 성능은 제일 안 좋지만 속도는 가장 빠른 것을 확인할 수 있습니다. 이때 추론 속도는 re-param 과정 없이 측정한 것입니다. 표4의 Table7은 RepVGG의 변형 모델 및 Related Works에서 설명했던 몇 모델 간의 성능 비교를 한 것입니다.
Full-featured reparam은 RepVGG-B0 베이스라인, Identity w/o BN은 identity branch에서 BN을 없앤 것, Post-addition BN은 모든 branch에서 BN을 없애고 그 branch들이 더해진 다음에 BN을 적용한 것입니다. Identity w/o BN와 Post-addition BN 두 경우 모두 베이스라인 보다 성능이 안좋습니다. +ReLU in branches는 각 branch에서 BN을 통과한 다음 ReLU도 통과시킨 것입니다. 모델의 비선형성이 증가했으니 당연히 성능이 조금 더 좋아졌지만, 또한 그렇기에 훈련 때 사용한 모델을 re-parameterization하지 못합니다. Residual Reorg는 RepVGG-B0와 같은 수의 3x3 conv를 가진 ResNet인데, 성능은 당연히 branch가 더 많은 RepVGG가 좀 더 좋습니다.
RepVGG를 제가 관심갖고 있는 Super Resolution에 적용하는 것은 어떨까요? SR은 원본 이미지의 특성을 그대로 보존하는게 중요하기 때문에 BN은 쓰지 않는 것이 정설입니다. 따라서 re-parameterization을 위해선 BN을 빼고 구현해야겠습니다. 그리고 SR이 원본 이미지의 특성을 최대한 사용하려고 하기 때문에, 이전에 포스팅 했던 MSRN 처럼 hieratical하게 branch를 엄청나게 사용하는 경향도 있습니다. 이 때문에 추론 속도가 느려질 수 있는데, 이러한 SR의 문제점을 RepVGG가 해결해줄 수도 있을 것 같습니다. 그리고 실제로 ACM 2021에서 발표된 "Edge-oriented Convolution Block for Real-time Super Resolution on Mobile Devices"라는 논문에서 re-parameterization을 SR에 적용한 것을 확인할 수 있습니다. RepVGG는 그 기술의 참신성과 효용성 덕분에 SR 뿐만 아니라 다양하게 활용되고 발전될 수 있는, 잠재성이 높은 모델이라고 생각합니다.
원 논문
: https://arxiv.org/pdf/2101.03697.pdf
참고 사이트
: https://junha1125.github.io/blog/artificial-intelligence/2021-04-26-RepVGG/
'딥러닝 & 머신러닝 > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (0) | 2024.07.28 |
|---|---|
| [논문 리뷰] Super Resolution - RFDN (ECCVW 2020) (0) | 2022.01.02 |
| [논문 리뷰] Super Resolution - MSRN (ECCV 2018) (0) | 2021.07.19 |
| [논문 리뷰] Super Resolution - ESPCN (CVPR 2016) (0) | 2021.06.18 |
| [논문 리뷰] Super Resolution - VDSR (CVPR 2016) (0) | 2021.06.18 |



