이번 포스팅에서는 "NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis" 논문을 리뷰하겠습니다. ECCV 2020의 best paper로 선정된 바 있으며, 이후 하나의 분야 자체가 되어, 3D rendering의 역사에 큰 획을 그어 나가는 중입니다. 현재는 기존 NeRF의 문제점을 고쳐나가거나, NeRF를 응용하는 논문이 많이 나오고 있습니다.
개요

NeRF는 3D 장면을 생성하고 렌더링하기 위한 딥러닝 기반의 컴퓨터 비전 기술입니다. 여기서 NeRF의 풀네임은 Neural Radiance Fields 인데요. 직역하면 '신경 복사장'이라는 이해할 수 없는 단어가 나옵니다. 그냥 특정 위치 (물체의 위치 정보와 물체를 바라보는 방향) 값을 입력하면 RGB 값을 출력하는 함수라고 생각하시면 됩니다.
NeRF의 궁극적인 목표는 실제 세계의 3D 장면을 모델링하여, 기존에 촬영하지 않은 새로운 시점에서의 장면 (novel view) 을 볼 수 있게 하는 것입니다. 기존에는 3D Scanner 등을 사용하여 Point Cloud, Mesh, Voxel 등으로 표현되는 3D 객체를 직접 렌더링했습니다. 하지만 NeRF는 3D 객체 자체를 생성하는 대신, 객체를 다양한 시점에서 바라보는 장면을 생성하는 Novel View Synthesis 기술을 제안합니다. 이를 통해 객체를 여러 각도에서 보다 현실감 있게 재현할 수 있습니다.
NeRF를 구성하는 각 기술에 대한 개요 설명을 하고, 그 다음에 각 기술에 대한 자세한 설명을 하겠습니다.
(a) NeRF의 입력은 물체의 위치 정보 (x, y, z)와 물체를 바라보는 방향 (θ, φ)가 함께 있는, 5차원 데이터입니다. 이때 θ: 방위각 (좌우), φ: 고도각 (상하)를 나타냅니다. 즉, Ray 상에서 샘플링된 점들의 정보 (x, y, z, θ, φ)가 입력으로 사용됩니다. 이때 Ray는 물체를 찍은 방향으로부터 물체를 향해 일직선으로 쏜 선을 의미합니다.
(b) NeRF의 출력은 샘플링된 점들에 대한 RGB 값과 물체의 밀도 σ입니다. 입력값으로부터 출력값을 얻기 위한 모델은 간단한 MLP (다층 퍼셉트론) 네트워크입니다. 여기서 말하는 밀도는, 그 값이 커지면 물체가 불투명해지고, 작아지면 물체가 투명해진다는 의미입니다. 추가로, 최적화를 위해 Positional Encoding을 사용합니다.
(c)+ (d) NeRF는 출력값을 볼륨 렌더링합니다. 볼륨 렌더링이란 MLP에서 얻은 Ray 내 점들의 RGB와 밀도 값을 합쳐 하나의 픽셀로 변환하는 과정을 뜻합니다. 볼륨 렌더링을 하는 이유는 바로, 물체의 픽셀 값에 영향을 미치는 것은 Ray 내의 모든 점들이기 때문입니다. 여기서도 추가적인 최적화를 위해, Hierarchical Volume Sampling을 사용합니다. 이후, 실제 픽셀 RGB 값과 볼륨 렌더링으로 예측한 픽셀 RGB 값 간의 MSE, 즉 렌더링 손실 함수를 계산해서 모델을 최적화합니다.
(a) : 5D Input (Position + Direction)
중요한 개념이라 다시 설명드리자면, Ray는 물체를 찍은 방향으로부터 물체를 향해 일직선으로 쏜 선을 의미합니다. Ray 내에 포함되는 점들(그림의 검은색 점들)의 3D 위치 (position) 는 (x, y, z)로 나타내며, Ray 방향을 나타내는 2D 시점 방향 (viewing direction) 은 (θ, φ)로 나타냅니다.
실제 예시 코드에서는 100개의 이미지와 이에 해당하는 100개의 카메라 포즈 값이 입력됩니다. 이때 이미지는 (x, y, z), 위치를, 카메라 포즈 값은 (θ, φ), 방향을 결정합니다. 카메라 포즈 값은 물체를 찍은 카메라의 위치로 이동시켜주는 '변환 행렬' (transform matrix) 의 값으로 표현하며, 특정 θ, φ에 대한 cos와 sin 값으로 구성됩니다.
이때, 카메라 포즈값인 변환 행렬은 extrinsic parameter입니다. 어떤 이미지를 찍은 카메라가 초기 위치에 있다고 할 때, 해당 카메라를 rotation과 translation을 통해서, 초기 위치에서 해당 이미지를 찍은 위치로 옮겨주는 역할을 합니다. 실제 코드 상에선 transforms.json 이라는 형태로, 각 위치의 이미지를 찍은 위치로 옮겨주는 4x4 변환 행렬이 있습니다.
해당 행렬은 카메라 속에서 실제 세계로, 즉 2차원 픽셀값을 3차원 공간 복셀값으로 변환해준다고 하여, camera-to-world matrix 라고도 합니다. 또, 해당 행렬의 역행렬은 world-to-camera matrix이며, 반대로 3차원 복셀값을 2차원 픽셀값으로 변환해줍니다. 해당 개념은 world-to-camera, camera-to-world 변환 과정에 대한 글을 보시면 이해에 좋을 것 같습니다. 한편 각 변환에는 extrinsic 뿐만 아니라 intrinsic parameter도 사용되는데, intrinsic parameter란 각 카메라에서 변하지 않는 정보, 즉 초점거리 (focal length, fx & fy) 와 카메라 렌즈 중심 좌표 (camera center, cx &cy) 등을 뜻합니다.
구체적인 입력 이미지의 예시를 들어보겠습니다. 위와 같은 입력 이미지가 400x400 해상도라면 한 이미지에는 160,000개의 픽셀, 즉 160,000개의 Ray가 있습니다. 즉, 한 이미지 상에서 160,000개의 Ray가 3D 물체의 방향으로 일직선을 쏘게 됩니다. 이 순간의 목표는 Ray 내 점들의 위치 정보 (x, y, z)와 Ray 방향 정보인 (θ, φ)를 모델 입력으로 사용하는 것입니다. 다시 말하는 것이지만, 물체의 픽셀 값에 영향을 미치는 것은 Ray 내의 모든 점들이기 때문입니다.
하지만 160,000개의 Ray 정보를 모두 사용하면 계산량이 매우 증가합니다. 따라서 1회 반복(iter)당 160,000개의 Ray 중 4,096개의 Ray를 샘플링합니다. 그러나 이때도 샘플링된 Ray 상에 있는 점들은 무한하게 많을 수 있기 때문에, 계산량이 무한대로 늘어납니다. 따라서 입력으로 들어가는 점들은 다시 샘플링을 통해 256개를 선택하여 입력합니다. 즉, "한 이미지에서 4,096개 Ray 샘플링 + 한 Ray에서 256개 점 샘플링"을 통해 1회 반복당 4,096 x 256개의 점들이 MLP 모델에 입력됩니다.
(b) : Output (Color + Density)
NeRF 모델은 MLP들로 구성되어 있으며, 각 포인트의 RGB 값과 밀도를 예측합니다. 입력으로는 위치 정보 γ(x: 가 사용되며, 이는 모델의 5번째 레이어에서 한 번 더 concat 됩니다. 이는 일종의 skip connection 으로 볼 수 있습니다. 출력은 총 두가지가 있습니다.
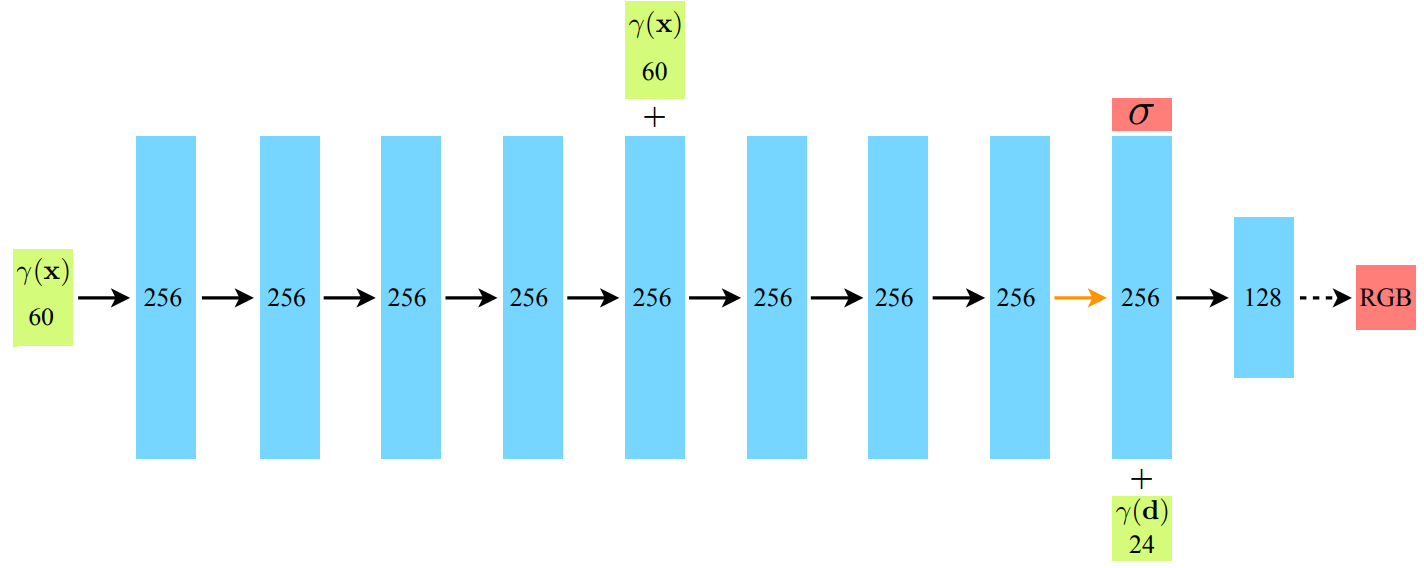
먼저 첫번째로, 9번째 레이어에서 밀도(𝜎)가 출력됩니다. 물체의 밀도는 각도와 상관없이 동일해야 하기 때문에, 처음 8개의 완전 연결 (Fully Connected, FC) 레이어에서는 위치 정보만으로 학습이 이루어집니다. 또한, 9번째 레이어에서 방향 정보 γ(d: θ,φ) 가 추가 입력되며, 마지막 레이어에서 최종 RGB 값이 출력됩니다. 색상은 물체를 보는 방향에 따라 달라지므로, 방향 값이 마지막 완전 연결 레이어의 입력으로 사용됩니다.
이때 γ(x)와 γ(d)가 아까 설명한 것처럼 3차원, 2차원이 아니라 60차원, 24차원으로 표현되어 있습니다. 이는 Postional Encoding을 통해 모델에 입력되는 정보량을 늘렸기 때문입니다. 이는 딥러닝 모델이 저주파수 (low frequency) 로 편향되어 학습되는 경향, 즉 결과 이미지를 표현할 때 저주파수에 해당하는 정보만 잘 표현하는 문제점을 해결하고, 고주파수 (high frequency) 까지 표현할 수 있게 합니다.

여기서, 저주파수에서 고주파수로 넘어갈수록 이미지의 더 세밀한 표현을 뜻하는 것으로 이해하시면 되는데요. Postional Encoding은 위치 정보의 작은 차이도 고차원으로 표현함으로써, 모델이 세밀한 차이를 잘 학습할 수 있도록 합니다. 좀 더 구체적인 예시를 들어보겠습니다. 예를 들어, (5, 5, 5)와 (5.1, 5, 5)와 같은 입력 차이는 MLP가 명확하게 인지하지 못합니다. 하지만 Positional Encoding을 통해 위치의 작은 차이도 잘 학습할 수 있게 되고, 이는 모델이 이미지를 고차원으로 잘 표현할 수 있게 해줍니다. 이러한 주장을 뒷받침 하는 연구인 Rahaman et al.에 따르면, 입력을 higher dimension으로 매핑시키면 모델이 high frequency variation을 가진 데이터를 더 잘 이해할 수 있다고 합니다. 위 그림에서도 볼 수 있듯, Positional Encoding이 없는 경우엔 이미지가 blur 되는 부분이 있는 걸 확인할 수 있습니다. (View dependence는 방향 정보 (θ,φ) 를 뜻합니다)
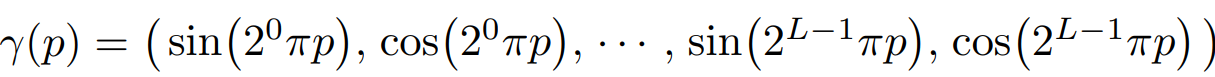
어떻게 γ(x)와 γ(d)가 각각 60차원, 24차원을 갖게 됐는지 위 수식을 통해 살펴보겠습니다. γ(x)에 대해선 60차원 데이터가 생성됩니다. (3 x (sin 10개 + cos 10개)) γ(d)에 대해선 L=4를 사용하고, 24차원 데이터가 생성됩니다. (3 x (sin 4개 + cos 4개)) 그런데 방향 정보인 γ(d)는 θ, φ로 이루어진 2차원 정보 아닐까요? 왜 여기선 갑자기 3차원으로 간주할까요? 그 이유는 사실 방향 정보도 3차원 공간 내부에서 표현되어야 하는 벡터이므로, 3개의 입력으로 계산되기 때문입니다. 로만 표현한 것은 3D 공간에서 하나의 좌표를 나머지 두 개로 나타낼 수 있기 때문으로 보입니다.
(c) + (d) : Volume Rendering + Loss
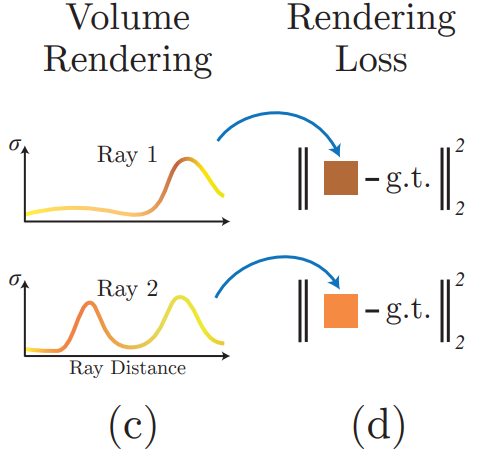
NeRF 모델에서는 MLP에서 얻은 Ray 내 점들의 RGB 값과 밀도 값을 결합하여 하나의 픽셀로 변환합니다. 이렇게 렌더링된 RGB 값은 실제 이미지의 RGB 값과 비교되어 MSE Loss를 통해 최적화됩니다.
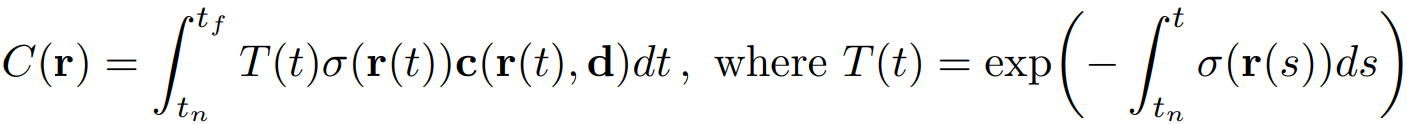

Ray 내의 점들은 이론적으로 무한개로, 연속적인 성질을 가지고 있습니다. 따라서 이를 하나의 픽셀로 변환하기 위해 적분을 사용합니다. 이 과정에서 투과도, 밀도, 색상값을 적분하여 최종 픽셀 값 C(r)을 렌더링합니다.
이때 t_n (near) 은 Ray의 시작 시점, t_f (far) 는 Ray의 끝 시점을 의미합니다. 즉, 투과도 T(t)는 t_n으로부터 특정 시점 t 까지의 density 값을 더한 값이 클수록 작아집니다. 다시 말해, 앞에 가려진 부분의 density가 클수록, 해당 시점 t 에서의 투명도가 작아진다는 개념입니다. 따라서 Ray 상의 전체 점들을 고려해 픽셀 한 개의 값을 결정하기 위해선, t_n에 더 가까운 점의 색상과 밀도를 더 반영하게 됩니다.
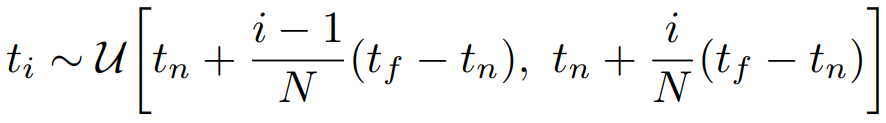
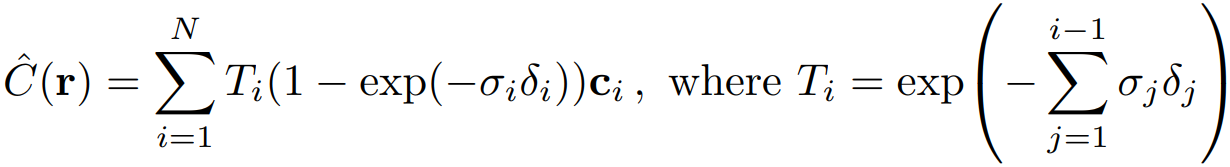
하지만 실제적으로도, 코드 상에서도 무한개의 점들을 적분할 수 없기 때문에, Ray 내 몇 개의 점을 샘플링합니다. 이때 Stratified Sampling을 사용합니다. Ray 내에서 몇 개의 점들을 샘플링할 때, 무작위로 점들을 뽑아낸다면, 어떤 경우 특정 구간에서만 많은 점들이 뽑히고, 다른 구간에선 별로 안 뽑힐 수도 있습니다. 따라서 Stratified Sampling에선 Ray를 n등분하여 각 등분한 구간에서 점들이 균일한 확률로 뽑히도록 설정합니다. 이로써 Ray의 여러 구간에서 점들을 샘플링하고, 비교적 연속적인 값에 대해 학습할 수 있습니다. 이때는 적분 대신 불연속 구간에서의 합을 통해 C_\hat(r)을 추정합니다.
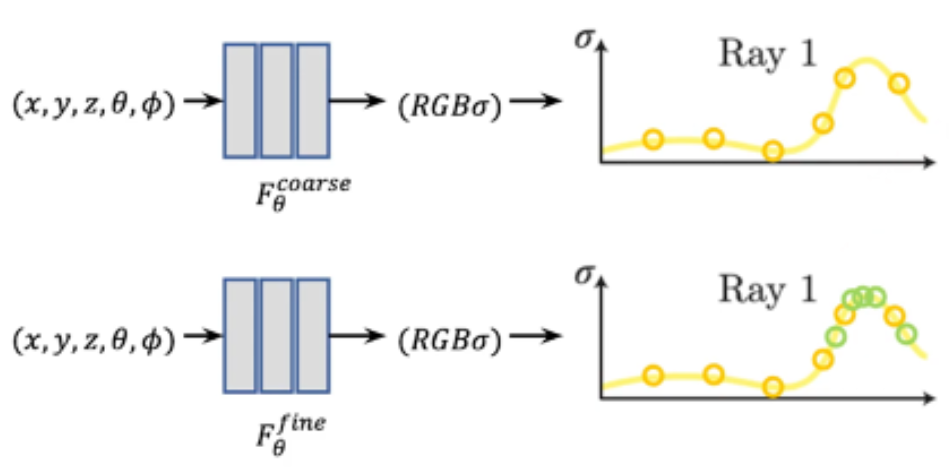
해당 과정까지를 기본 모델인 Coarse network라 하며, 추가 성능 향상을 위한 Fine network도 존재합니다. Stratified sampling을 해도, 여전히 Ray 중 객체가 잘 없는 점이 뽑히는 경우 발생합니다. 그러한 점에서보단, 객체가 존재하는 Ray의 구간에서 추가 학습을 하면 효과가 더 좋을 것입니다.
이러한 이유에 기반하여, Fine network에선 밀도가 높은 부분에서 추가 샘플링을 진행합니다. 즉, Ray 전체에서 샘플링하여 학습 (Coarse network) 을 진행한 후, 밀도가 크게 나온 구간들을 골라내어 그 부분에서 다시 추가 샘플링을 진행합니다. (Fine network) 위 그림의 그래프에서 볼 수 있듯, 밀도 𝜎가 높은 구간에서 Fine network의 학습이 진행됩니다.
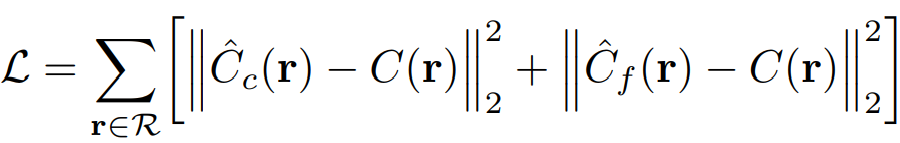
이때 여기서 말하는 "추가 샘플링"이라는 것이 바로 Hierarchical Volume Sampling 입니다. 즉 Ray 전체에서 샘플링하여 (ex. 64개의 점) 학습을 하고 (Coarse network), 학습된 결과로부터 밀도가 크게 나온 구간들을 측정하고 골라내어, 그 부분에서 다시 더욱 샘플링 (ex. 128개의 점) 하여 추가 학습 (Fine network) 을 진행합니다. 이로써, Coarse & Fine network의 RGB 값 예측 결과와 실제의 RGB 값을, MSE loss를 통해서 비교하여 최적화합니다. 위 수식은 해당 과정을 의미합니다.
실험 결과
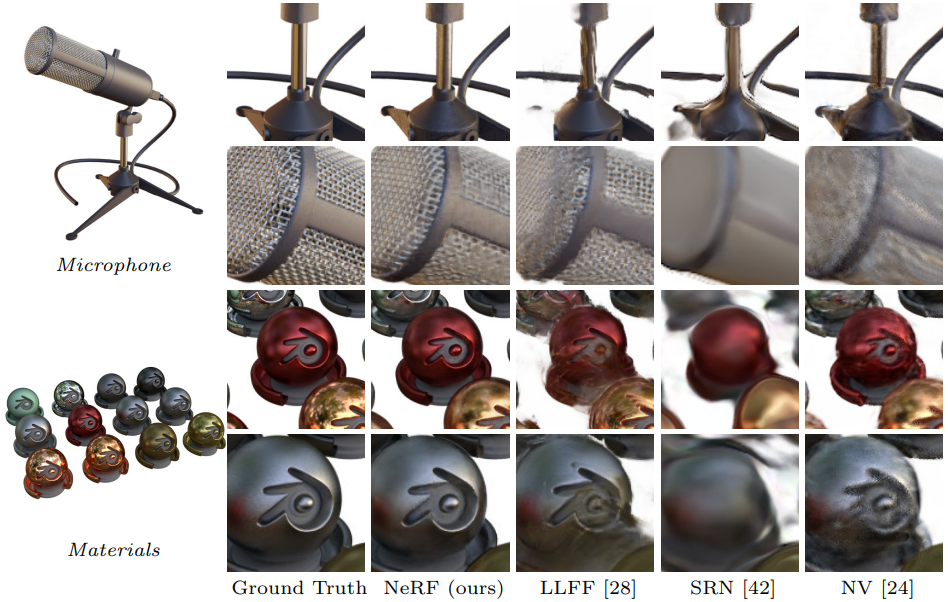


훈련 데이터셋은 Synthetic renderings of objects와 Real images of complex scenes이며, 이들은 다른 논문 (LLFF) 에서 가져온 데이터와 저자들이 직접 만든 데이터입니다. 시각적 결과에서는 다른 모델에 비해서 NeRF가 디테일을 살리고, 뒤쪽까지 잘 생성합니다. Ghosting effect 또한 없는 것을 확인할 수 있습니다. NeRF의 위력은 프로젝트 페이지 등에서 동영상으로 확인했을 때 더 여실히 드러납니다. (https://www.matthewtancik.com/nerf)
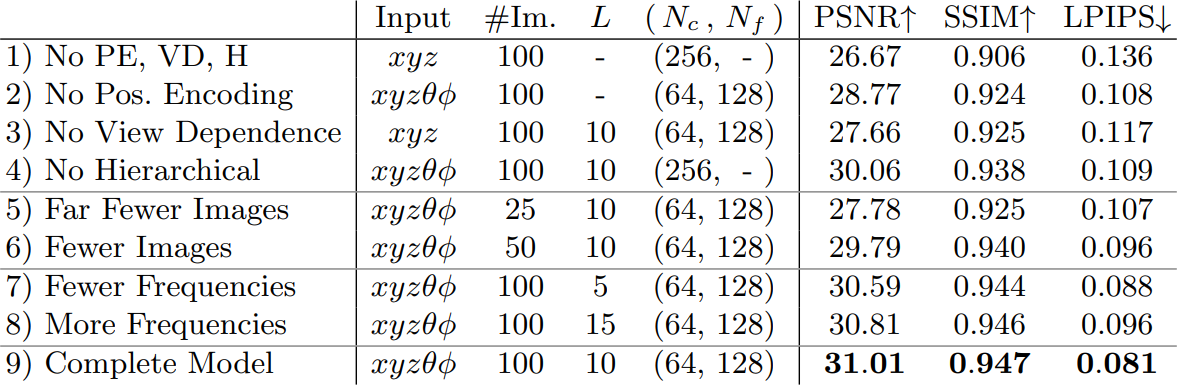
Ablation Studies 결과입니다. 각 행에 대한 설명은 아래와 같습니다.
1) ~ 4) : Positonal Encoding (L), View Dependence (θ,φ), Hierarchical Sampling (Fine net.) 의 영향을 확인합니다.
5) ~ 6) : 입력으로 들어가는 Scene의 갯수를 조절합니다. 즉, 더 적은 방향에서 바라본다고 가정합니다.
7) ~ 8) : Positional Encoding에서 L 값을 조절합니다. 즉, 더 적은 주파수 (= 더 적은 위치 정보) 를 넣는다고 가정합니다.
9) : 모든 것이 논문에서 제안하는 값으로 들어간, 완전한 모델을 의미합니다.
결론
해당 논문은 물체를 바라보는 Ray 상의 점을 렌더링 하는 Novel View Synthesis 방법을 처음으로 제안했습니다. 하지만 이러한 NeRF에도 여러가지 단점이 존재합니다.
1) 훈련 및 렌더링 속도가 느리다.
2) 정적인 장면에 대해서만 성능이 좋다.
3) 같은 환경에서 촬영한 이미지에 대해서만 성능이 좋다.
4) 다양한 시점의 너무 많은 장면으로 이루어진 훈련셋이 필요하다.
5) 입력값으로 카메라의 intrinsic & extrinsic parameter가 필요하다.
6) 한 객체에 대해 학습된 모델은 한 객체만 렌더링 할 수 있다.
이러한 단점들을 해결하기 위해, Plenoxel, D-NeRF, NeRF in the wild, InstantNGP, SCNeRF, GIRAFFE 같은 방법들이 계속해서 제안되고 있습니다. 또, 최근에는 똑같이 3D 렌더링이 목적이지만 NeRF와는 방법이 전혀 다른, 3D Gaussian Splatting이라는 기법을 활용한 방법들도 나오고 있습니다. 해당 모델에 대해서는 추후 새로운 포스팅을 통해 소개하도록 하겠습니다.
아래는 제가 해당 포스팅을 작성할 때 참고했던 게시물들입니다. 감사합니다.
https://kyujinpy.tistory.com/16
[NeRF 논문 리뷰] - NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
* 이 글은 NeRF에 대한 논문 리뷰이고, 핵심만 담아서 나중에 NeRF Code를 이해할 때 쉽게 접근할 수 있도록 정리한 글입니다. * 코드와 함께 보시면 매우 매우 도움이 될 것이라고 생각이 들고, 코드
kyujinpy.tistory.com
https://nuggy875.tistory.com/168
[NeRF] NeRF 논문 리뷰 : Neural Radiance Fields for View Synthesis
Detection을 주로 연구하다가 3D 쪽에 관심을 갖게 되어 NeRF라는 방법(이제는 자체가 분야가 된..)을 접하게 되었고, 흥미가 생겨 관련하여 연구중에 있습니다. 이번 글에서는 NeRF를 처음 제안한 논
nuggy875.tistory.com
[논문 리뷰] NeRF 간단 설명 & 원리 이해하기 | 새로운 방향에서 바라본 view를 생성하는 기술
- paper : NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis / ECCV2020 NeRF 논문이 공개된지도 시간이 꽤 흘렀는데, 2020 ECCV에서 공개됐을 때만 해도 굉장히 신기하고 획기적인 view synthesis 방법으
mvje.tistory.com
NeRF 구현 톺아보기 (feat. Camera to World Transformation)
NeRF 의 기본 개념은 간단한 편이지만, 막상 Dataloader 부터 from scratch 로 구현하려고 하면 어려운 부분이 많다. 그중에서도 ray casting 에 필요한 ray direction 과 ray origin 을 어떻게 구하는지 수식과 대
velog.io
https://modulabs.co.kr/blog/nerf-from-2d-to-3d/
NeRF: 2D 이미지를 3D로 바꿔준다고요?
요즘 인공지능 분야에서 핫한 분야가 무엇일까요? 아마도 NERF가 아닐까 싶습니다. NeRF(Neural radiance Fields)는 2D 이미지를 3D로 변환해주는 모델입니다. 이번 콘텐츠에서는 NeRF에 대해 알아보겠습니
modulabs.co.kr
'딥러닝 & 머신러닝 > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] 3D Gaussian Splatting for Real-Time Radiance Field Rendering (0) | 2025.01.01 |
|---|---|
| [논문 리뷰] Descanning: From Scanned to the Original Images with a Color Correction Diffusion Model (0) | 2024.12.21 |
| [논문 리뷰] Super Resolution - RFDN (ECCVW 2020) (0) | 2022.01.02 |
| [논문 리뷰] CNN - RepVGG (CVPR 2021) (0) | 2021.12.28 |
| [논문 리뷰] Super Resolution - MSRN (ECCV 2018) (0) | 2021.07.19 |



