RFDN은 다음과 같이 한 문장으로 말할 수 있겠습니다. "feature distillation connection (FDC) 이라는 기술을 제안해서 residual feature distillation을 하는 모델 RFDN을 만들었다. RFDN은 multiple feature distillation connection을 이용해서 구별점이 나타나는 (즉, 특이한) feature representation들을 학습할 수 있다. 그리고 RFDN의 메인 블록인 shallow residual block (SRB) 을 사용함으로써 가벼운 모델 용량을 유지함과 동시에 residual learning의 장점까지 얻을 수 있다."
~ Residual Feature Distillation Network for Lightweight Image Super-Resolution ~
# 1. Introduction
SR 모델은 SRCNN, VDSR, EDSR 등 깊은 모델일수록 성능이 좋아지는게 보통이지만, 실제 세계에 적용하긴 아직 무겁습니다. 이 논문에선 빠르고 가벼운 SR 모델을 만드는데 집중합니다. 그리고 그러한 SR 모델은 성능과 복잡도 간의 좋은 trade-off 관계를 유지해야 합니다.
가벼운 모델을 만들기 위해 DRCN, DRRN은 parameter sharing이라는 기법으로 가중치 수를 줄이지만, 그것을 위해 사용해야 하는 recursive module에서 발생하는 loss를 줄이기 위해 모델의 depth나 width이 증가해야합니다. 그렇게 되면 모델 크기는 작아지는 대신 연산량과 추론 시간은 증가하게 되며, 이는 실제 세계의 적용을 어렵게 만듭니다.

CARN-M이라는 모델은 cascading 구조를 사용해서 가벼워 모바일 기기에서도 잘 작동했지만, 성능 저하가 있습니다.
IDN (information distillation network)은 distilled(증류된) feature, 즉 정보를 잘 압축해서 갖고 있는 feature를 얻기 위해 channel split operation을 사용한다. 네트워크의 중간 feature를 채널 차원 상의 두 파트로 나눠서, 하나는 유지시키고 또 다른 하나는 이후의 컨볼루션 레이어를 통과시키며 더욱 process하는 것입니다. 이로써 적당한 모델 크기에서도 좋은 성능을 낼 수 있었습니다.
IMDN (information multi-distillation network)은 IMDB (Information Multi-Distillation Block) 라는 것을 이용해 더 발전시킨 IDN의 형태입니다. 구체적으론, IMDB 안에서 channel split operation이 여러 번 반복된 형태입니다. 한번 반복될 때마다, IDN과 마찬가지의 과정을 겪습니다.
IMDN은 AIM 2019 Super Resolution 부문에서 높은 PSNR 성능과 짧은 추론 시간을 달성하며 실제 세계에서의 적용 가능성이 있음을 보였습니다. 그러나 모델의 크기, 즉 파라미터 수는 VDSR, MemNet, IDN에 비해 더 많았습니다. 그래서 저자들은 이 IMDN을 더 가볍게 만들 여지가 있다고 생각했습니다.
지금까지 소개한 IDN과 IMDN의 핵심 포인트는 IDM (information distillation mechanism) 입니다. IDM은 네트워크를 통과하는 feature를 채널을 기준으로 두 부분으로 나누어서, 한 부분은 그냥 그대로 통과시켜 유지하고 (retain) , 나머지 한 부분은 이후 컨볼루션 레이어를 통과시키며 정제하는 (refine) 것입니다. 저자들은 이 IDM이 효율적이지 못하고 네트워크 디자인에 있어서도 유연하지 못하다고 주장합니다.
이 논문에선 IDM에 관한 좀더 편한 해석을 제공하고, IDM에서 사용한 기술보다 더 가볍고 유연한 FDC (feature distillation connection) 라는 기술을 제안합니다. 저자들은 성능과 추론 시간 사이에 적절한 trade-off 관계가 증명된 IMDN을 베이스라인으로 사용하지만, 여기서 FDC를 사용함으로써 더욱 가볍게 만듭니다. 거기에 더해, SRB (shallow residual block) 라는 것 또한 도입하여 성능까지 더 올립니다. 이렇게 IMDN에 FDC와 SRB를 추가해서 성능은 높이, 무게는 가볍게 만든 모델이 RFDN (residual feature distillation network) 입니다.
# 2. Related Works
논문의 related works는 이전까지의 SR 모델들과 그 문제점 (not lightweight, slow inference speed) 들을 소개하고, IDN, IMDN에 대한 설명을 다시 합니다. 이는 Introduction에서 충분히 소개하였으니 PPT 슬라이드 한장으로 Related Works 챕터를 대신하겠습니다.
# 3. Proposed Methods
그림2.(a)의 IMDB는 Introduction에서도 계속 말했듯이 feature의 몇 부분은 유지, 나머지 부분은 정제되는 구조를 보입니다. 하지만 이렇게 distilled된 feature들은 쓸모없는 가중치들이 많은 3x3 conv에 의해 생성됩니다. 게다가, PRM (progressive refinement module, 그림의 회색 부분) 의 오른쪽 가지 부분, 즉 feature 정제 부분의 파이프라인이 채널 split 부분과 겹치기 때문에, 이 부분만을 위한 identity connection을 사용하기 힘듭니다. 즉, channel split을 하면서 채널 수가 줄어들어 identity connection 사용이 어렵다는 뜻입니다.
저자들은 이 IMDB를 다시 생각해본, 그림2.(b)의 IMDB-R을 제안합니다. channel split을 먼저 한 다음에, 각 부분을 2개의 다른 3x3 conv에 통과하게 했고, 그럼으로써 채널 수를 조정할 수 있습니다. 이처럼 IMDB-R은 IMDB 보다 더 유연한 구조를 갖고 있는걸 알 수 있습니다. 이 덕분에 바로 다음에 설명할 RFDB에서 SRB를 이용한 identity connection도 이뤄질 수 있었습니다.
그림2.(c)의 RFDB는 IMDB-R에서 왼쪽 branch인 retain 부분의 3x3 conv들을 1x1 conv로 바꿨고, 오른쪽 branch인 refine 부분을 맨 마지막 3x3 conv만 유지하고 나머지는 그림2.(d)의 SRB로 모두 바꿨습니다. 그림2.(b)처럼 채널 수를 줄이는데 3x3 conv를 쓸 수도 있겠지만 이는 비효율적입니다. 왜냐하면 나중에 채널 별로 concat 하기 위해선 feature 텐서의 이미지 가로 세로 부분은 그 수치가 같아야 하는데, 3x3 conv는 여러번 거칠수록 feature 텐서 사이즈가 작아지기 때문입니다. padding과 stride를 조정해서 같게 할 수는 있지만, 그보다는 1x1 conv를 써서 텐서 사이즈는 생각 안하고 오로지 채널 수만 신경 쓰는게 더 효율적이고 가중치 수도 줄일 수 있어서 좋다고 합니다. 저자들은 이렇게 기능적으로 channel split operation과 같지만 더욱 효율적이고 가벼운 용량으로 하는 구조를 FDC (feature distillation connection) 로 명명했습니다.
더 나아가, 3x3 conv, ReLU, identity connection으로 이루어진 SRB (shallow residual block) 를 도입해서 추가적인 파라미터 필요없이 residual learning의 장점을 local하게 쓸 수 있도록 했습니다. 참고로 추가적인 파라미터가 필요없다는 건 그림2.(b)의 3x3 conv가 유지되서 그런 것입니다. SRB는 그림2.(c)에서 자주색 부분으로 나타납니다.
그리고 각 블록에서 attention을 담당하는 CCA Layer는 E-RFDN에서 그림3과 같은 구조를 갖습니다. E-RFDN이란 저자들이 AIM 2020 efficient SR 부분에서 우승을 위해 만든 RFDN 개선 모델입니다. 이때 ESA (Enhanced Spatial Attention) 블록은 저자들의 이전 논문 "Residual feature aggregation network for image super-resolution"에서 소개된, spatial attention을 하는 블록입니다.
RFDB로 이루어진 최종 RFDN의 구조는 그림4와 같습니다. 여기서 x는 인풋 LR (low resolution) 이미지, h(.)는 첫 3x3 conv, F_0는 3x3 conv를 통과한, 첫번째 feature를 의미합니다. H_k는 k번째 RFDB, F_k-1과 F_k는 k번째 RFDB의 인풋과 아웃풋 feature를 의미하며, H_assemble은 RFDB에서 나온 feature concat 과정 이후 나오는 1x1 conv와 3x3 conv를 말합니다. 각 RFDB에서 나온 정보가 집약되어 conv를 통해 처리된 feature인 F_assemble과 맨 처음 feature인 F_0를 residual connection하고, pixel shuffle인 R 함수를 통해서 feature를 upscaled된 이미지로 만듭니다. loss function은 L1 norm을 사용합니다.
# 4. Experiments


Dataset details와 Implementation details는 위와 같습니다.
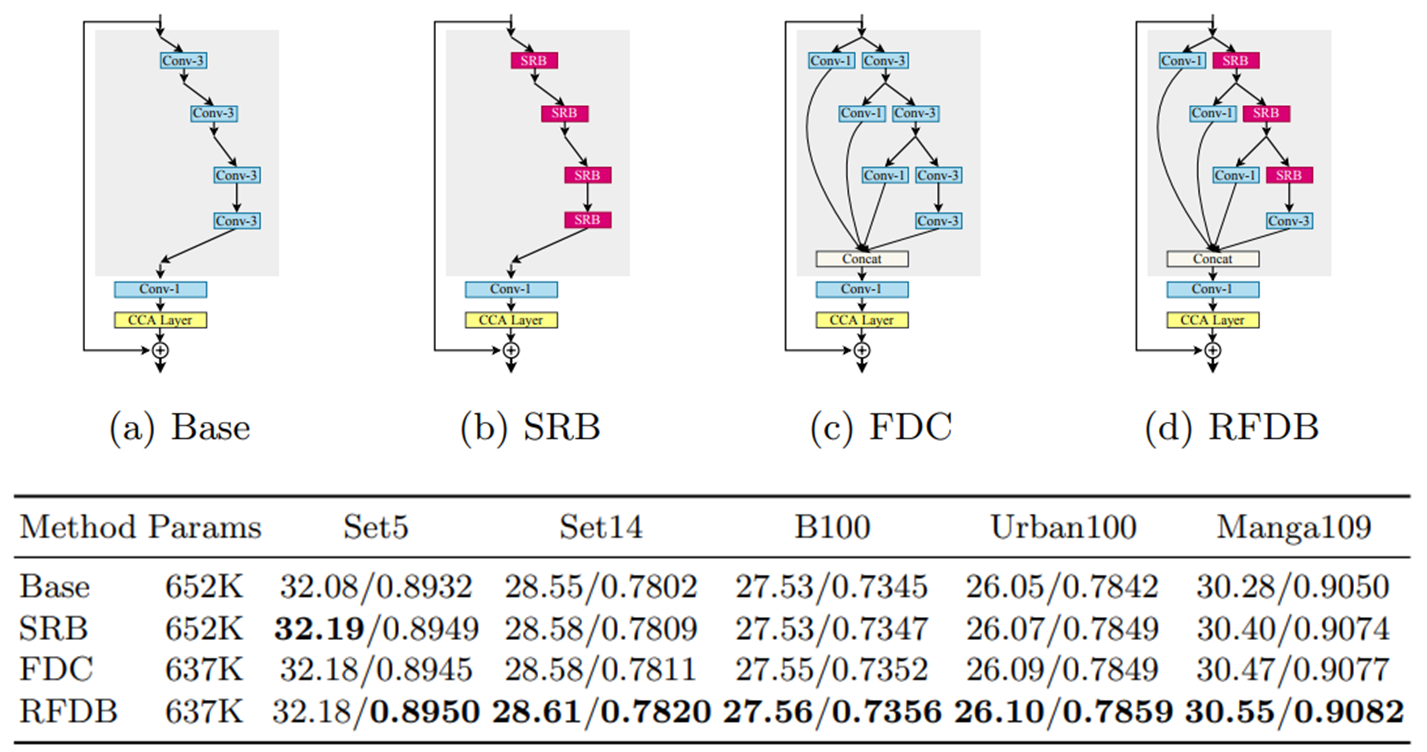
표1과 그림5는 3x3 conv로만 이루어진 baseline (a)를 기준으로, baseline의 3x3 conv를 SRB로 바꾼 (b), baseline에 FDC, 즉 retain 부분을 추가한 (c), 그리고 RFDB (d)를 각각 비교하는 Ablation study 결과와 그림입니다. 실험 결과 baseline보다 SRB, FDC가 추가된 것이 미세하게 더 좋고, 둘 다 추가된 RFDB가 가장 높은 성능을 냅니다.

표2는 distillation rate에 따른 RFDN의 성능을 나타냅니다. 서로 다른 distillation rate에 따라 feature distillation connections 부분에서 아웃풋 채널 수가 달라집니다. 실험 결과, 파라미터 수 대비 성능은 distillation rate = 0.5일 때 가장 좋은 것으로 나타났습니다.
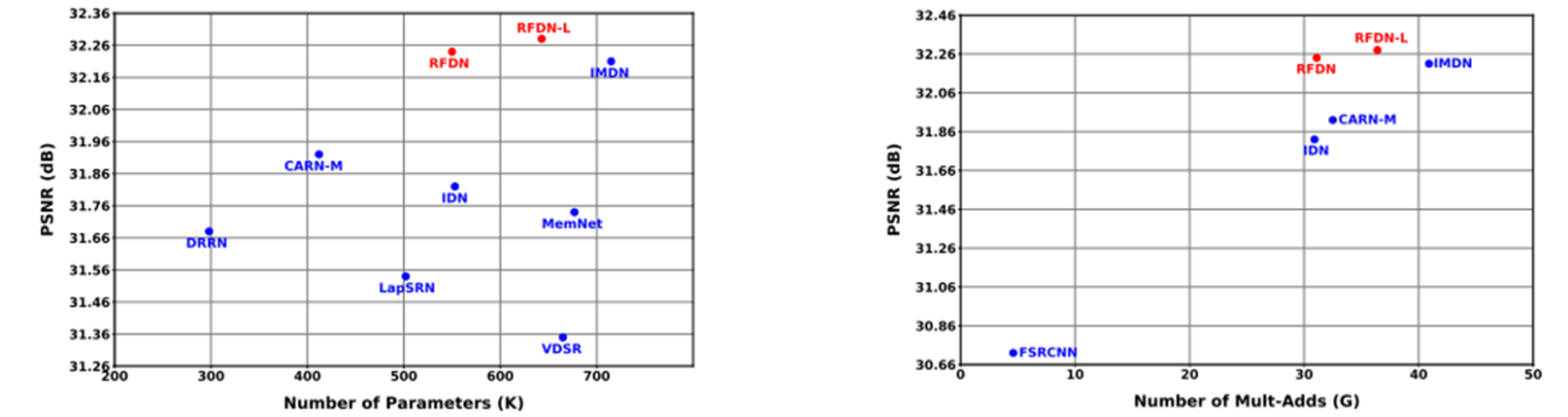
표3은 Set5 x4 데이터셋을 사용해서, DRRN, LapSRN, VDSR, MemNet, IDN, CARN-M, IMDN 그리고 RFDN, RFDN-L 간의 성능(PSNR)과 파라미터 수, 성능과 Multi-Adds 수를 그래프로 그려서, 그들의 모델이 더 복잡성은 적고 속도는 빠름을 나타내고 있습니다. 그리고 표에는 나와있지 않지만, 추론 속도도 44FPS로, IMDN과 비슷하지만(comparable) 더 정확하고 가볍다고 합니다.
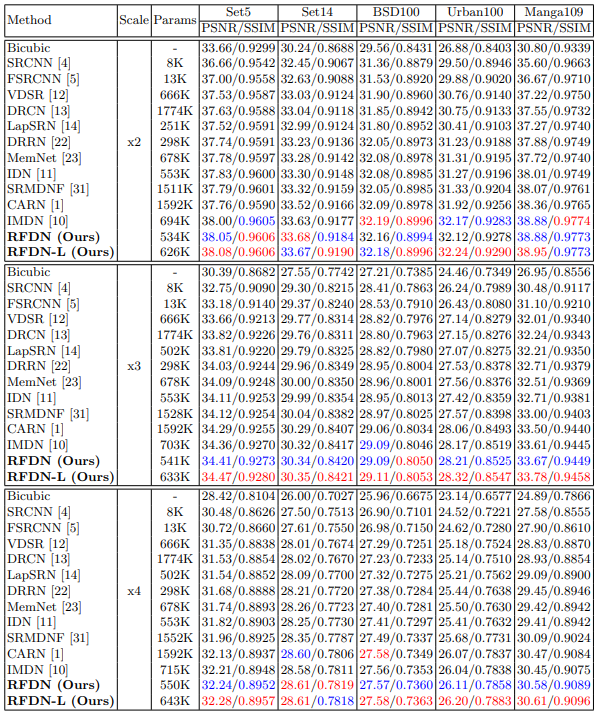
표4는 모델별, 스케일별 PSNR과 SSIM을 비교한 표입니다. RFDN 모델들이 당시의 SOTA 모델보다 더 월등한 것을 볼 수 있습니다.

표5는 지금까지 계속 비교를 해왔던 IMDN과 RFDN 간의 수치적 비교입니다. scaling factor x4에서, 똑같은 조건으로 처음부터 훈련시킨 결과입니다. RFDN이 IMDN 보다 적은 파라미터 수를 갖지만, 모든 데이터셋에서 더 좋은 성능을 내는 것을 알 수 있습니다.
원 논문
'딥러닝 & 머신러닝 > 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] Descanning: From Scanned to the Original Images with a Color Correction Diffusion Model (0) | 2024.12.21 |
|---|---|
| [논문 리뷰] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis (0) | 2024.07.28 |
| [논문 리뷰] CNN - RepVGG (CVPR 2021) (0) | 2021.12.28 |
| [논문 리뷰] Super Resolution - MSRN (ECCV 2018) (0) | 2021.07.19 |
| [논문 리뷰] Super Resolution - ESPCN (CVPR 2016) (0) | 2021.06.18 |



